
HappyHorse 1.0 vs Seedance 2.0: Which AI Video Model Wins?
In the rapidly evolving world of AI video generation, two standout models have recently captured the attention of creators, developers, and video professionals. HappyHorse 1.0 and Seedance 2.0 represent completely different approaches to transforming text prompts and images into dynamic video content. As a group of technical experts dedicated to exploring cutting-edge AI video models, we have analyzed extensive data across public benchmarks and practical workflows to bring you this comprehensive review.
Whether you focus on short narrative clips or complex multimodal productions, understanding the distinct strengths of these models can help guide your next creative project. Let us dive deeply into their architectures, features, and practical applications in a friendly and objective manner.
Technical Architectures: The Engine Under the Hood
To truly appreciate what makes these models unique, we must first look at their underlying engineering. Their structural differences directly influence generation speed, output stability, and visual coherence.
HappyHorse 1.0: The Unified Single-Stream Approach Industry analysis indicates that HappyHorse 1.0 utilizes a unified single-stream Transformer architecture containing around 40 layers. In this highly efficient setup, text, video, and audio tokens are processed together in one continuous sequence without relying on separate cross-attention branches. This allows the model to maintain exceptional internal continuity and tight integration across all modalities. Combined with an ultra-fast 8-step denoising process, this single-stream method prioritizes sheer visual flow and rapid generation for short clips.
Seedance 2.0: The Dual-Branch Diffusion Master Conversely, Seedance 2.0 (developed by ByteDance's renowned research team) relies on a meticulously crafted dual-branch diffusion Transformer architecture. One branch is dedicated entirely to video frames, while the other manages audio waveforms. These branches are connected via precise cross-attention mechanisms. By treating audio as a primary input rather than an afterthought, this setup ensures millisecond-level synchronization. For creators working on dialogue-heavy content, this dual-branch method is an absolute game-changer.
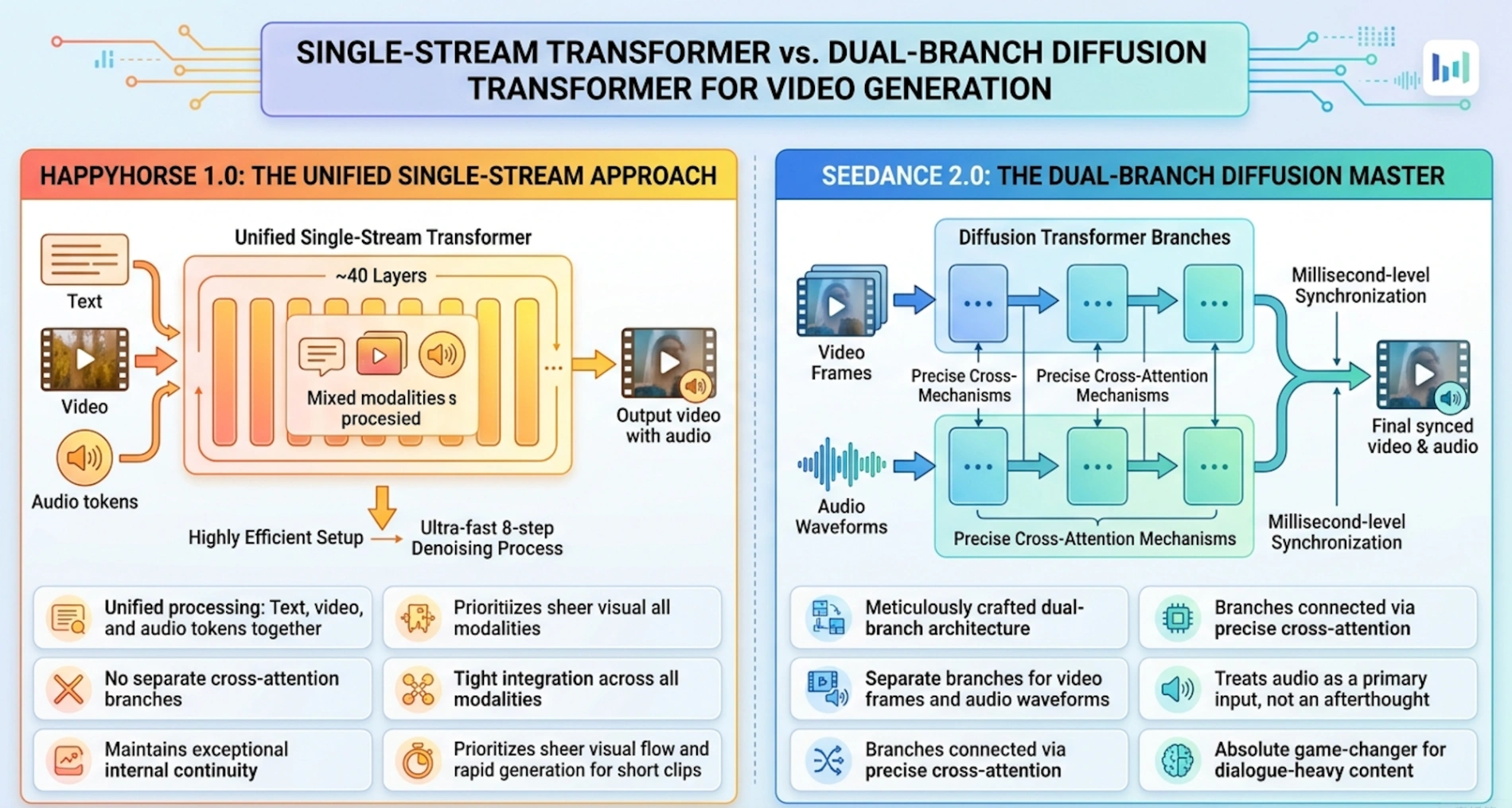
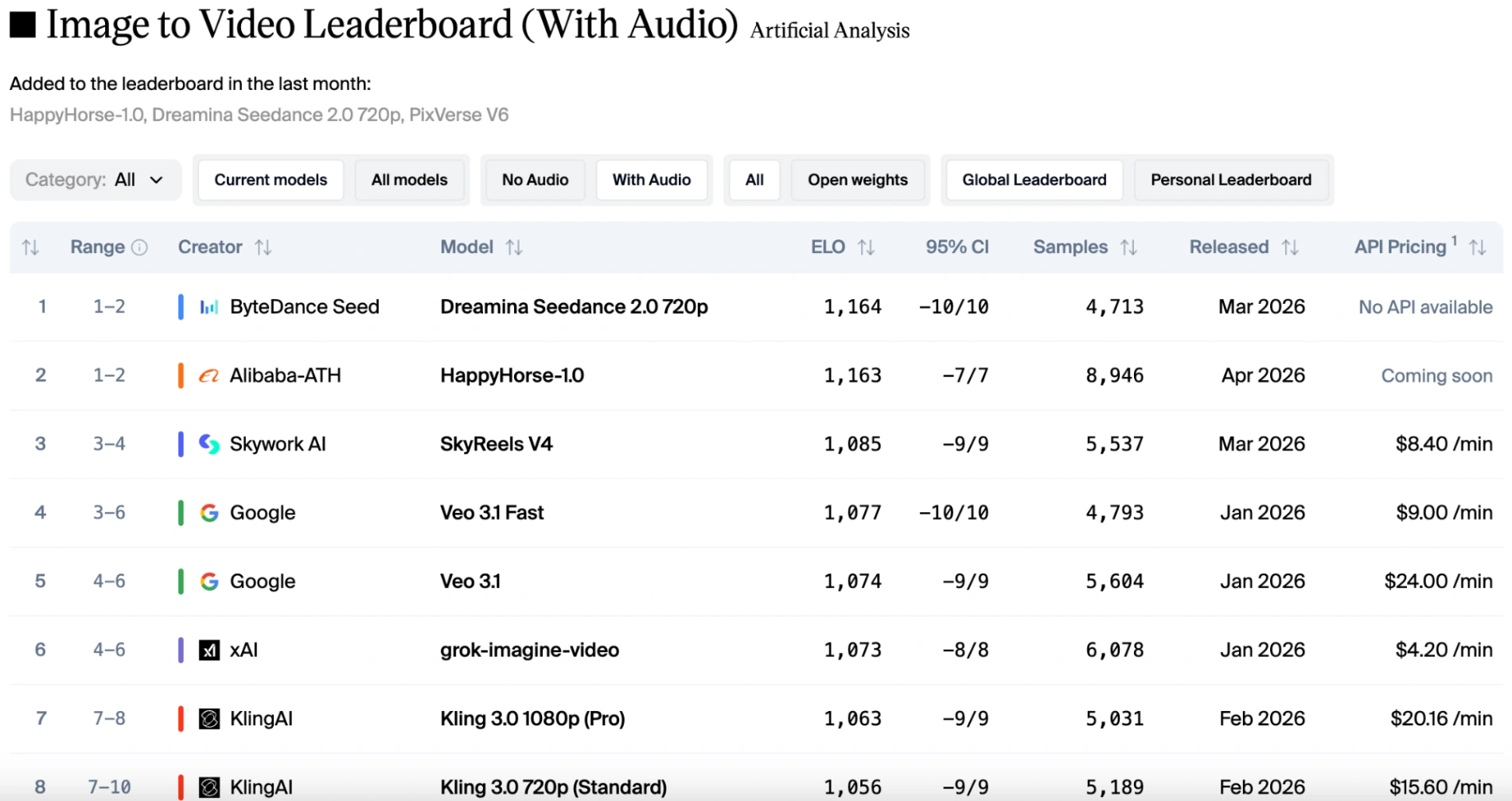
Visuals vs. Audio: What the Leaderboards Reveal
Public leaderboards, such as the Artificial Analysis Video Arena, provide fantastic blind-tested insights into human preferences. The data reveals a fascinating story where the winner depends entirely on whether sound is involved.
In the pure visual categories (text-to-video and image-to-video without audio), HappyHorse 1.0 holds a commanding lead. It consistently outperforms Seedance 2.0 by a margin of 50 to 100 Elo points. Voters overwhelmingly favor HappyHorse for its natural camera drift, sharp cinematic details, and ability to preserve subject identity from reference images.
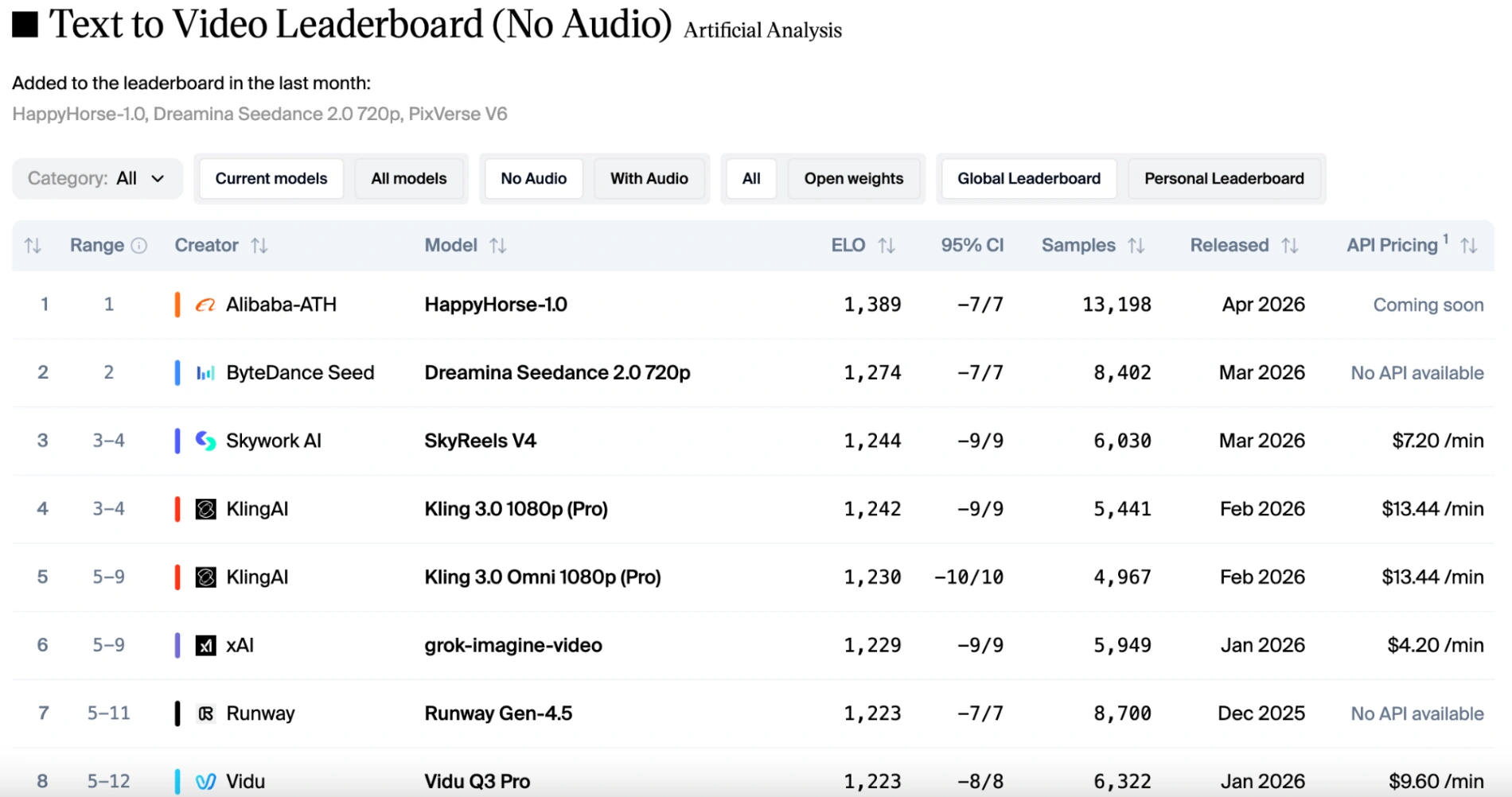
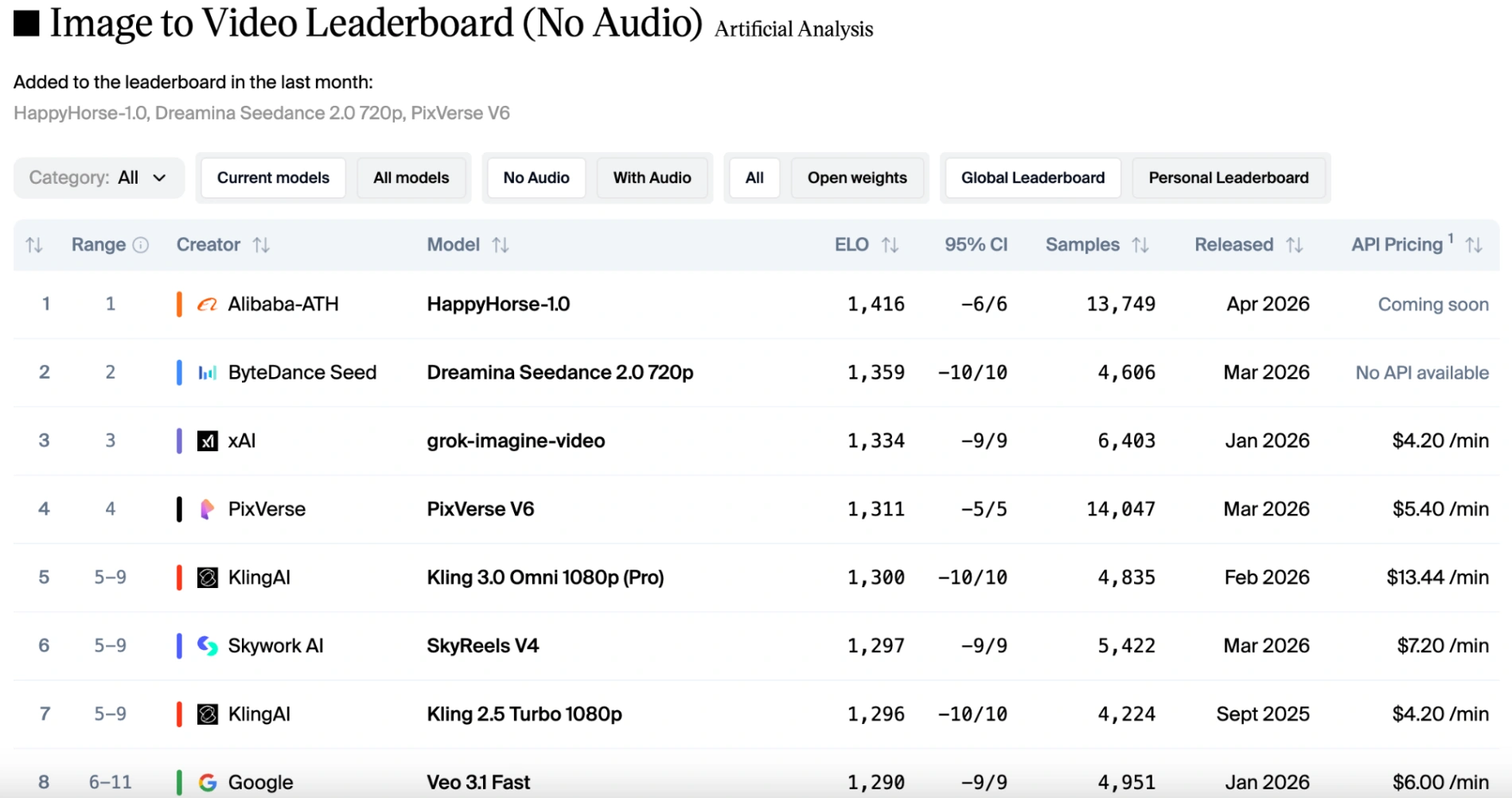
However, if audio factors are taken into account, the rankings shift slightly. HappyHorse 1.0 remains in first place for image-to-video (without audio). Seedance 2.0 reclaims the top spot for image-to-video (with audio), but HappyHorse is only one point behind, making them almost evenly matched. Thanks to Seedance 2.0's native multimodal capabilities, it delivers stable motion paired with perfectly synchronized sound effects and dialogue. While HappyHorse 1.0 remains competitive and supports multiple languages, it trails slightly behind Seedance when intricate audio-visual harmony is the primary judging criteria.
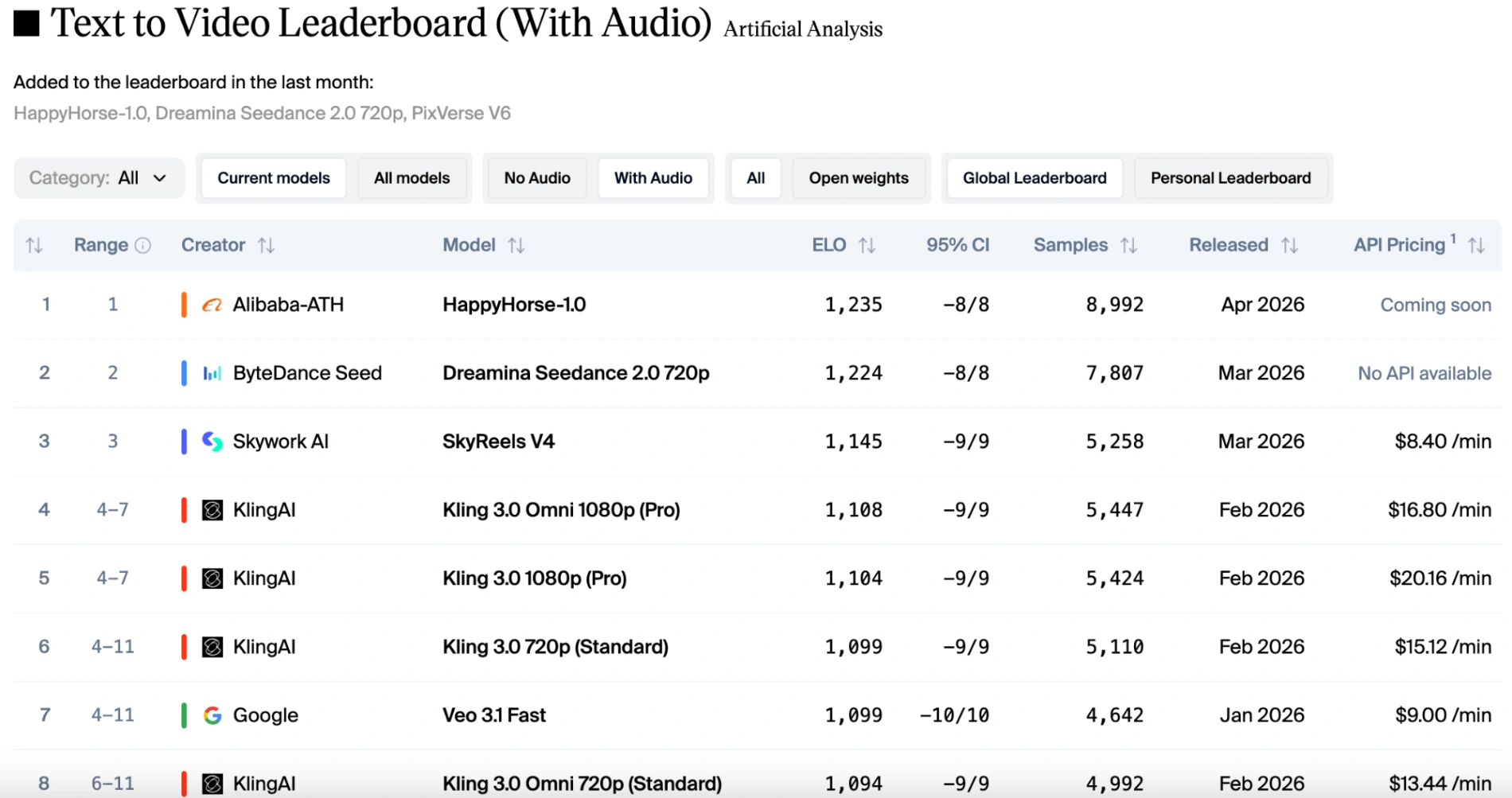
Feature Comparison: Inputs, Outputs, and Controls
A side-by-side look at their core capabilities highlights how these models cater to entirely different production styles.
HappyHorse 1.0 is highly practical and production-friendly for rapid outputs. It supports crisp 720p and 1080p resolutions, offering preset generation durations from 3 to 15 seconds. Creators will love its flexibility with aspect ratios (including 16:9, 9:16, and 1:1), making it perfect for social media campaigns or mobile ads. Its image-to-video conversion is incredibly strong, allowing users to animate concept art seamlessly.
Seedance 2.0, on the other hand, operates like a comprehensive "director's workstation". It pushes the boundaries by supporting resolutions up to 2K. What truly sets it apart is its massive input capacity. In a single prompt, a user can provide up to 9 reference images, 3 video clips, and 3 audio clips. This allows creators to steer lighting, character consistency, and camera movement with unparalleled precision.
Below is a concise comparison table summarizing their key features:
| Feature | HappyHorse 1.0 | Seedance 2.0 |
|---|---|---|
| Model Provider | Alibaba (China) | ByteDance (China) |
| Primary Architecture | Unified single-stream Transformer | Dual-branch diffusion Transformer |
| Core Strength | Raw visual coherence and smooth image-to-video | Multimodal inputs and precise audio synchronization |
| Max Resolution | 1080p cinematic | Up to 2K (depending on configuration) |
| Input Flexibility | Text, images (highly robust I2V) | Text, images (up to 9), video (up to 3), audio (up to 3) |
| Output Durations | Supports video duration ranging from 3 to 15 seconds | Flexible continuous generation from 1 to 15 seconds |
| Supported Ratios | 16:9, 9:16, 1:1, 4:3, 3:4 | Multiple formats supported (21:9, 16:9, 4:3, 1:1, 3:4, 9:16) |
| Audio Integration | Optional add-on, multilingual support (English, Chinese, Japanese, Korean, German, and French) | Native joint generation, phoneme-level lip sync, and supports more than 8 languages. |
| Release Status | Released on April 27, 2026. | Released. API access is now fully open. |
Practical Use Cases: Which Should You Choose?
Choosing the right tool ultimately comes down to the specific needs of your creative workflow. No single model is perfect for every scenario, and understanding their practical trade-offs is essential.
When to use HappyHorse 1.0: If your project begins with approved still images (such as poster art or product photography) and you need quick, stunning animation, HappyHorse 1.0 is extraordinary. It is highly recommended for short narrative teasers, stylized character sequences, and fast-moving social media edits. If absolute visual continuity and a cinematic atmosphere are your top priorities, this model delivers a breathtaking first-pass result.
When to use Seedance 2.0: Seedance 2.0 shines brightest in complex, director-style workflows. When you are producing short dramas, music videos, or commercials that require multiple camera angles, synchronized lip movements, and specific character references, Seedance is the clear winner. Its ability to process multiple references heavily reduces the need for tedious post-production adjustments. Furthermore, as of early 2026, Seedance 2.0 is highly accessible through various consumer platforms and reliable API proxies, making it incredibly production-ready for immediate commercial use.
Final Thoughts
The AI video landscape is advancing at a staggering pace, and both HappyHorse 1.0 and Seedance 2.0 are pushing the boundaries of what independent creators can achieve. HappyHorse 1.0 provides an inspiring glimpse into the pinnacle of silent visual motion, while Seedance 2.0 offers the robust, deeply controllable tools that professional directors need right now.
We highly encourage you to experiment with both models to see which one naturally fits your artistic process. As the technology continues to mature, we will undoubtedly see even more exciting updates. To stay informed on the latest generative AI trends, tutorials, and model comparisons, be sure to explore more resources with us at happyhorsesai.com!
Written by: HappyHorsesAI Research Team
Last updated: April 27, 2026