

HappyHorse - The latest AI video model from Alibaba
HappyHorse is the latest AI video model from Alibaba's ATH AI Innovation Unit. HappyHorse-1.0 ranks #1 on Artificial Analysis Video Arena. It supports all four video generation modalities: Text to Video and Image to Video, each with and without native audio.
Unified Audio and Video Synthesis
HappyHorse 1.0 simplifies the creative process by generating both high-quality video and synchronized sound effects directly from a single text prompt. By processing video and audio tokens within a unified Transformer sequence, the model ensures that auditory elements naturally align with on-screen actions (such as a splashing wave or engine noise), which helps reduce the need for additional audio post-production.

Consistent Image to Video Animation
For bringing static images to life, this model demonstrates strong performance on the Artificial Analysis Video Arena, including a notable Elo score of 1416 in the image to video (without audio) track. It focuses on maintaining character consistency and preserving environmental details, making it a practical option for animating concept art, portraits, and product photos.
Physics-Aware Motion Modeling
To address common visual issues like "unnatural", distorted movements in AI video, HappyHorse utilizes an optimized motion engine designed to respect real-world physics. This helps produce fluid human gaits, realistic fluid dynamics, and stable camera pans. By understanding physical constraints, the model significantly reduces the warping artifacts often seen in earlier generations of video tools.
Native Multilingual Prompt Understanding
As a native multimodal model, HappyHorse directly processes prompts in multiple languages (including English, Chinese, and Japanese) without relying on intermediate translation steps. This allows users to input culturally specific descriptions in their native language, helping to maintain the accuracy and subtle visual nuances of the original text prompt.
Efficient 8-Step Generation Process
Technical efficiency is a key focus for HappyHorse 1.0, which achieves clear video outputs in just 8 denoising steps. By leveraging an optimized Transformer architecture and advanced sampling techniques, the model delivers a 1.2x end-to-end acceleration. This faster generation process allows creators to test ideas and iterate on their projects more comfortably.
Accurate Lip-Sync and Dialogue Matching
The model integrates dedicated lip-sync capabilities designed to match spoken dialogue with character mouth movements. By targeting an "ultra-low WER" (Word Error Rate), HappyHorse ensures that generated speech aligns naturally with the visual elements. This feature streamlines the animation workflow by minimizing the need for manual timing adjustments in external software.
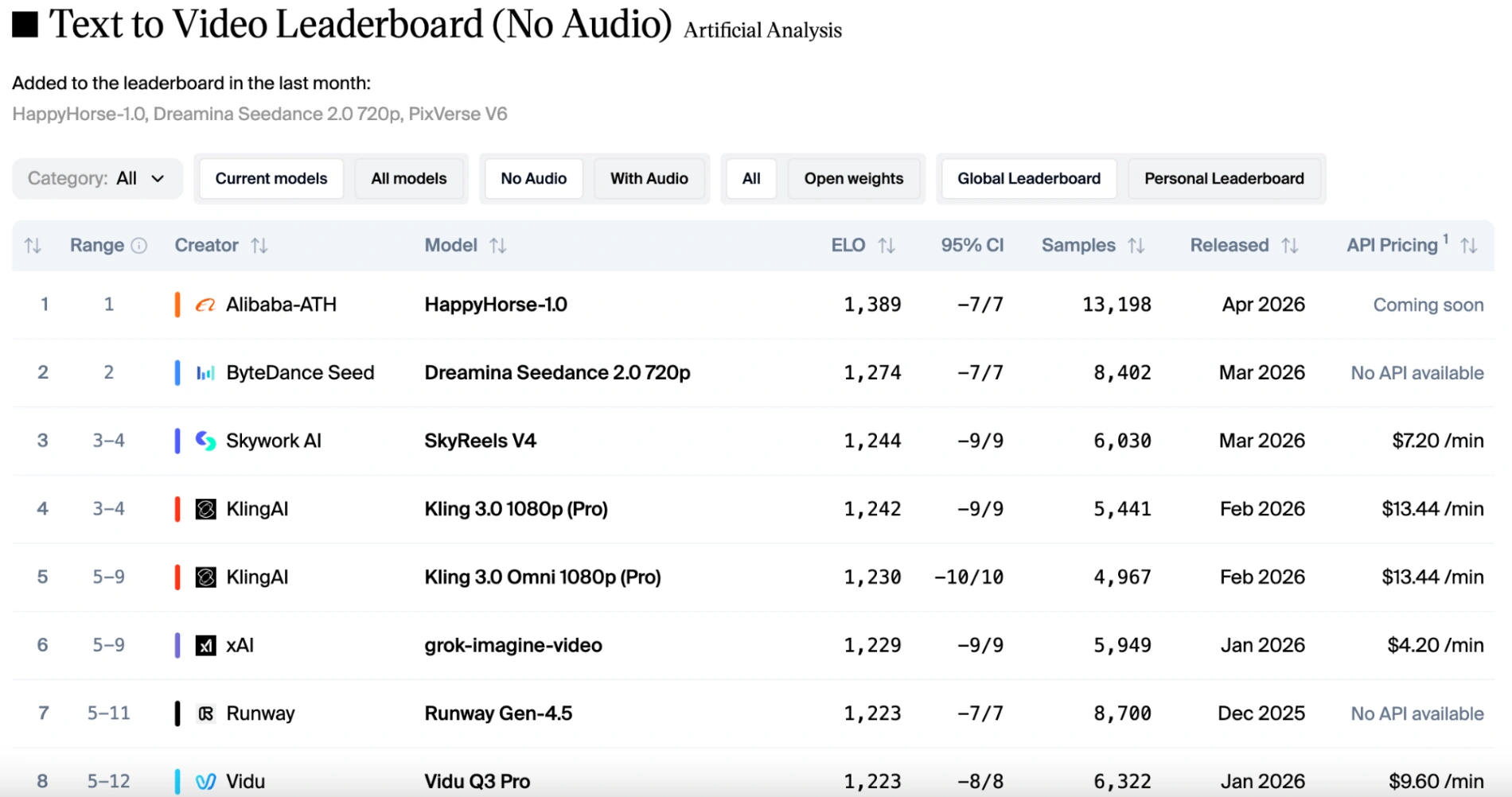
Happy Horse ranked first in the text-to-video (without audio) track with 1389 Elo points, leaving the second-place Dreamina Seedance 2.0 by nearly 115 points.
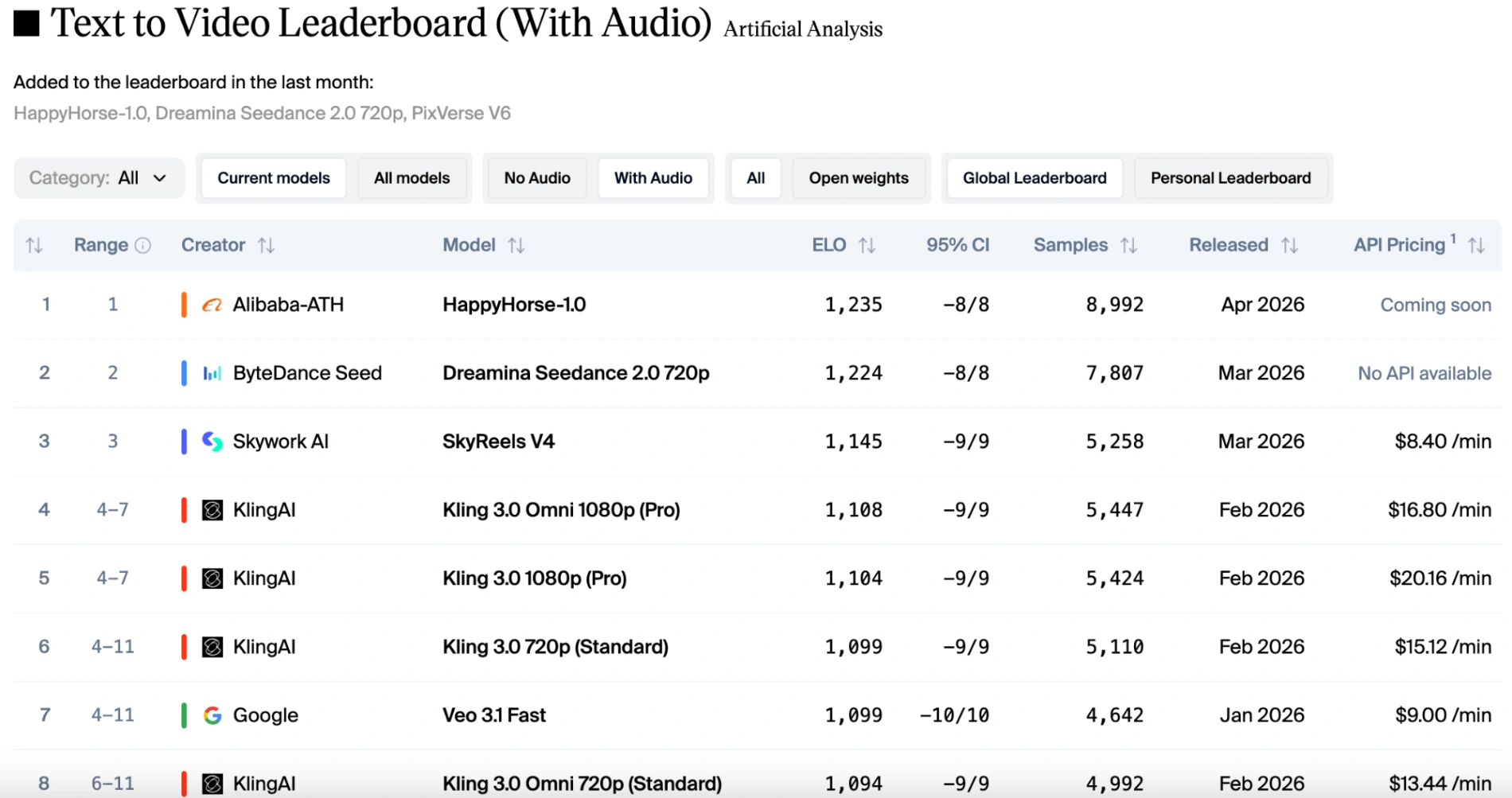
Even in the text-to-video (with audio) category, Alibaba's latest AI video model ranked first in the Elo rankings, leading Dreamina Seedance 2.0 720p by 11 points.
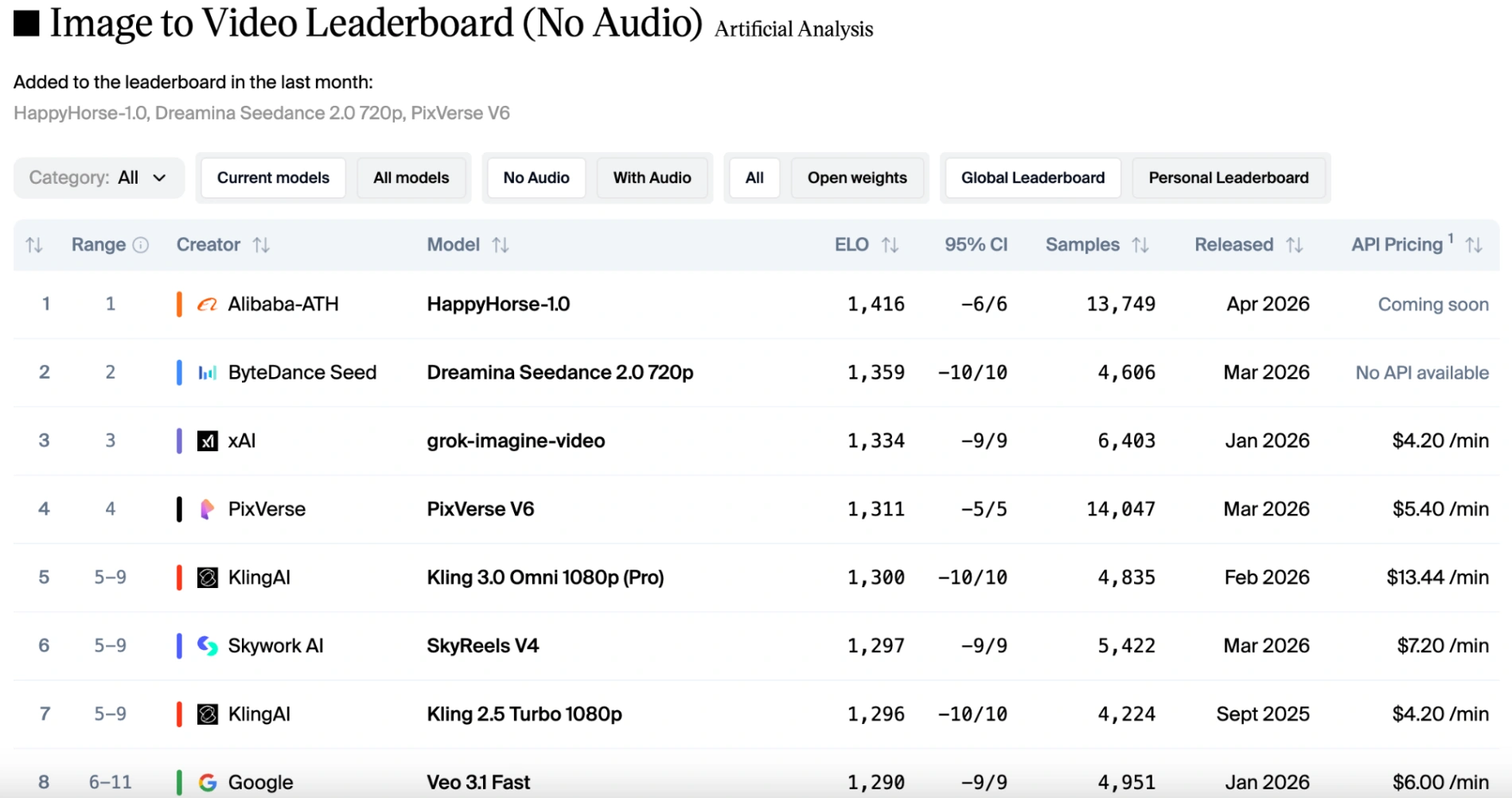
In the image-to-video (without audio) category, it achieved an astonishingly high score of 1416, setting a new record for Alibaba's video model on this leaderboard.
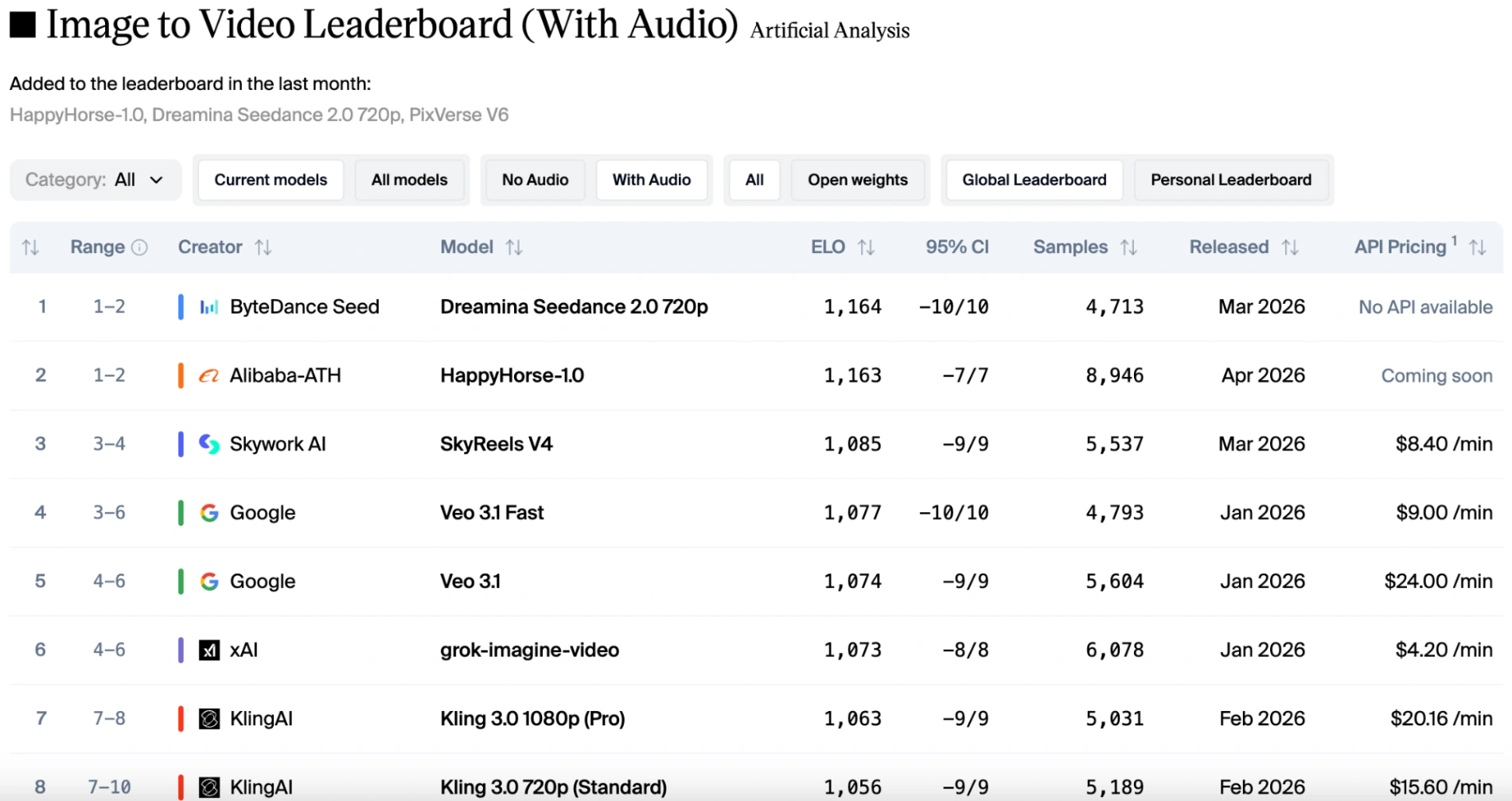
Even in the audio track, which has extremely high requirements for audiovisual coordination, this "happy horse" is on par with Seedance 2.0's Elo score.
Prompt: A Pixar-style short about a nervous little traffic cone who dreams of being a finish line pylon at a major race. Other cones mock its ambitions. A construction worker accidentally places it at a marathon finish line. The cone's painted face shifts from terror to joy as runners pass. Confetti falls on its cone head. Other cones watch on TV, inspired. Audio: Traffic sounds becoming crowd cheers, inspirational swelling music.
Prompt: A basketball bouncing on an empty indoor court, creating a loud, rhythmic echo with every slap against the polished hardwood floor, punctuated by the sharp squeak of rubber sneakers.
Prompt: A flashlight beam exploring a cave system, illuminating wet limestone formations. The light catches crystalline calcite deposits that glitter and flash. Where the beam passes through shallow standing water, it creates bright caustic patterns on the submerged floor. Stalactites cast long, swinging shadows as the flashlight moves. Audio: Dripping water echoing, footsteps on wet rock, breathing in enclosed space.
Prompt: 1.Person starts walking forward naturally. Realistic, continuous gait with smooth arm and head movements. No foot sliding. 2.A massively leaning Jenga tower. A trembling hand miraculously extracts a middle block. The tower sways but holds. Onlookers lean back, then exhale with relieved laughter. Audio: tense silence, wood sliding, collective gasp, relieved laughter. 3.Pixar-style animation: A freckled girl with wildly curly red hair runs through a windy wildflower meadow. Features hyper-realistic hair simulation (independent bouncing curls, shimmering sunlight highlights, natural secondary motion when she stops). Warm subsurface scattering on skin. Audio: joyful laughter, rushing wind, uplifting orchestral score.
Social Media Content Creation
Creators can produce engaging short videos for platforms like TikTok or YouTube Shorts efficiently. By utilizing the rapid generation process and native audio features, influencers can maintain high posting frequencies while significantly reducing manual audio editing time.
Marketing and Brand Commercials
Advertising teams can create high-quality brand commercials from simple text descriptions or product photos. The native multilingual prompt support allows for seamless global marketing, enabling teams to generate culturally relevant localized campaigns easily.
Game Development Prototyping
Game developers can rapidly prototype cinematic cutscenes and environmental animations. With the unified audio and video synthesis, studios can generate synchronized spatial audio alongside the visuals, helping to visualize the final game atmosphere early in the development cycle.
Digital Art Animation
Digital artists can transform static illustrations or concept art into immersive moving pieces. Leveraging the strong image to video capabilities of the model, creators can maintain strict character and environmental consistency without losing the original artistic style.
Cinematic Narrative Storytelling
Independent filmmakers can streamline the pre-production and visualization of short films. The physics-aware motion engine and precise lip-sync capabilities allow directors to create complex narrative sequences with realistic human movements and synchronized dialogue.
E-commerce Product Visualization
Retailers can elevate their online storefronts by turning static product shots into dynamic showcase videos. The model ensures physical accuracy and adds perfectly matched sound effects (such as fabric rustling or mechanical clicks), providing an engaging virtual experience for online shoppers.
