

HappyHorse - Il più recente modello di video AI da Alibaba
HappyHorse è il più recente modello di video AI dall'Unità di Innovazione AI ATH di Alibaba. HappyHorse-1.0 si classifica al primo posto su Artificial Analysis Video Arena. Supporta tutte e quattro le modalità di generazione video: da testo a video e da immagine a video, ciascuno con e senza audio nativo.
Sintesi unificata di audio e video
HappyHorse 1.0 semplifica il processo creativo generando sia video di alta qualità che effetti sonori sincronizzati direttamente da un unico prompt di testo. Elaborando token video e audio all'interno di una sequenza Transformer unificata, il modello garantisce che gli elementi uditivi si allineino naturalmente con le azioni sullo schermo (come un'onda che si infrange o il rumore di un motore), il che aiuta a ridurre la necessità di post-produzione audio aggiuntiva.

Animazione consistente da immagine a video
Per dare vita a immagini statiche, questo modello dimostra prestazioni forti su Artificial Analysis Video Arena, incluso un notevole punteggio Elo di 1416 nella traccia da immagine a video (senza audio). Si concentra sul mantenere la coerenza dei personaggi e preservare i dettagli ambientali, rendendolo un'opzione pratica per animare concept art, ritratti e foto di prodotti.
Modellazione del movimento consapevole della fisica
Per affrontare problemi visivi comuni come movimenti "innaturali" e distorti nei video AI, HappyHorse utilizza un motore di movimento ottimizzato progettato per rispettare la fisica del mondo reale. Questo aiuta a produrre andature umane fluide, dinamiche dei fluidi realistiche e panoramiche della camera stabili. Comprendendo i vincoli fisici, il modello riduce significativamente gli artefatti di deformazione spesso visti nelle generazioni precedenti di strumenti video.
Comprensione nativa dei prompt multilingue
Come modello multimodale nativo, HappyHorse elabora direttamente prompt in più lingue (incluso inglese, cinese e giapponese) senza fare affidamento su passaggi di traduzione intermedi. Ciò consente agli utenti di inserire descrizioni culturalmente specifiche nella loro lingua nativa, aiutando a mantenere l'accuratezza e le sfumature visive sottili del prompt di testo originale.
Processo di generazione efficiente in 8 passaggi
L'efficienza tecnica è un focus chiave per HappyHorse 1.0, che raggiunge output video chiari in soli 8 passaggi di denoising. Sfruttando un'architettura Transformer ottimizzata e tecniche di campionamento avanzate, il modello offre un'accelerazione end-to-end di 1.2x. Questo processo di generazione più veloce consente ai creatori di testare idee e iterare sui loro progetti più comodamente.
Sincronizzazione labiale precisa e corrispondenza dei dialoghi
Il modello integra capacità dedicate di sincronizzazione labiale progettate per corrispondere ai dialoghi parlati con i movimenti della bocca dei personaggi. Mirando a un "WER ultra-basso" (Tasso di Errore di Parola), HappyHorse garantisce che il discorso generato si allinei naturalmente con gli elementi visivi. Questa funzionalità semplifica il flusso di lavoro di animazione minimizzando la necessità di regolazioni manuali di tempistica in software esterni.
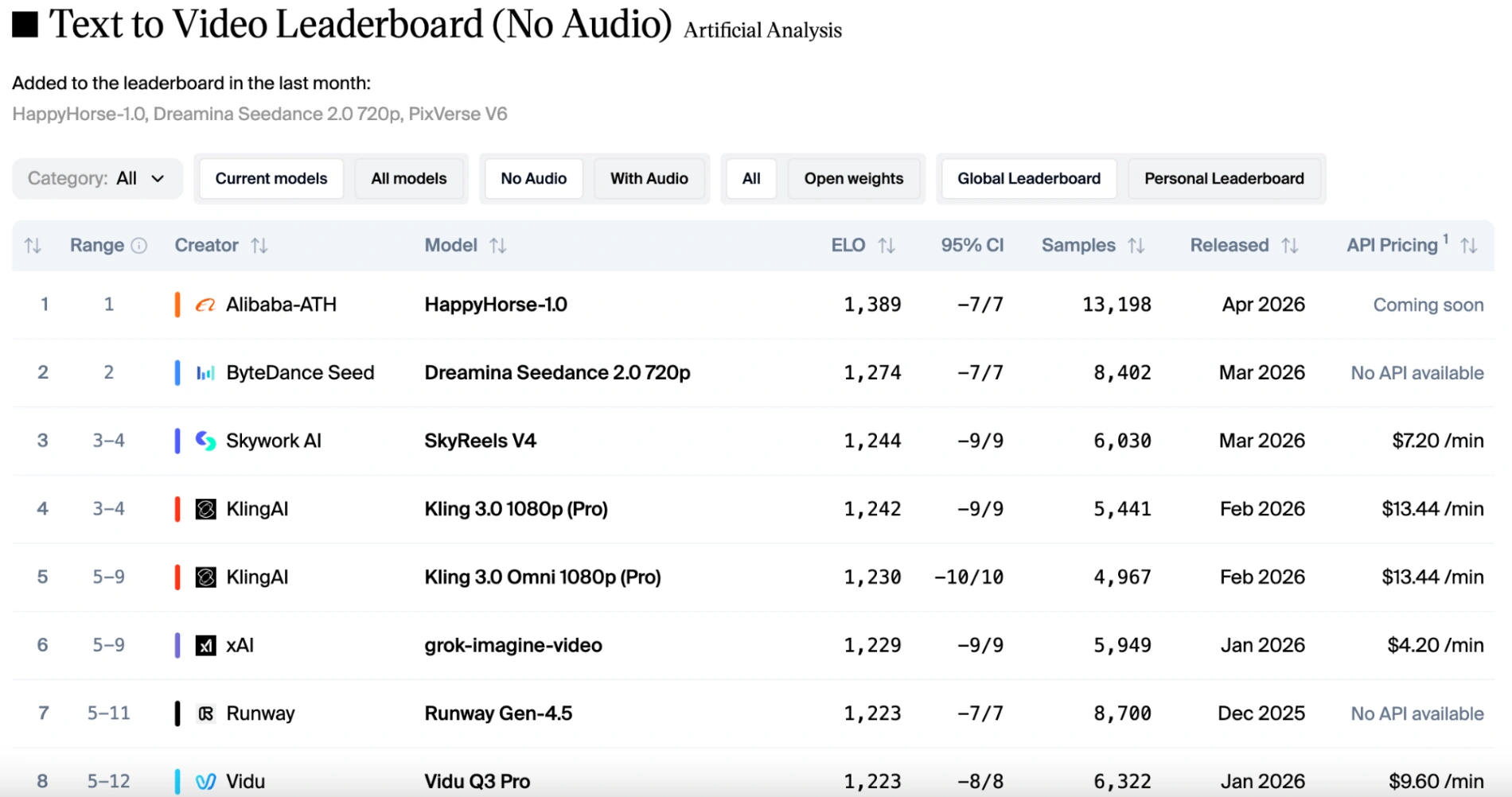
Happy Horse si è classificato primo nella traccia da testo a video (senza audio) con 1389 punti Elo, lasciando il secondo posto Dreamina Seedance 2.0 di quasi 115 punti.
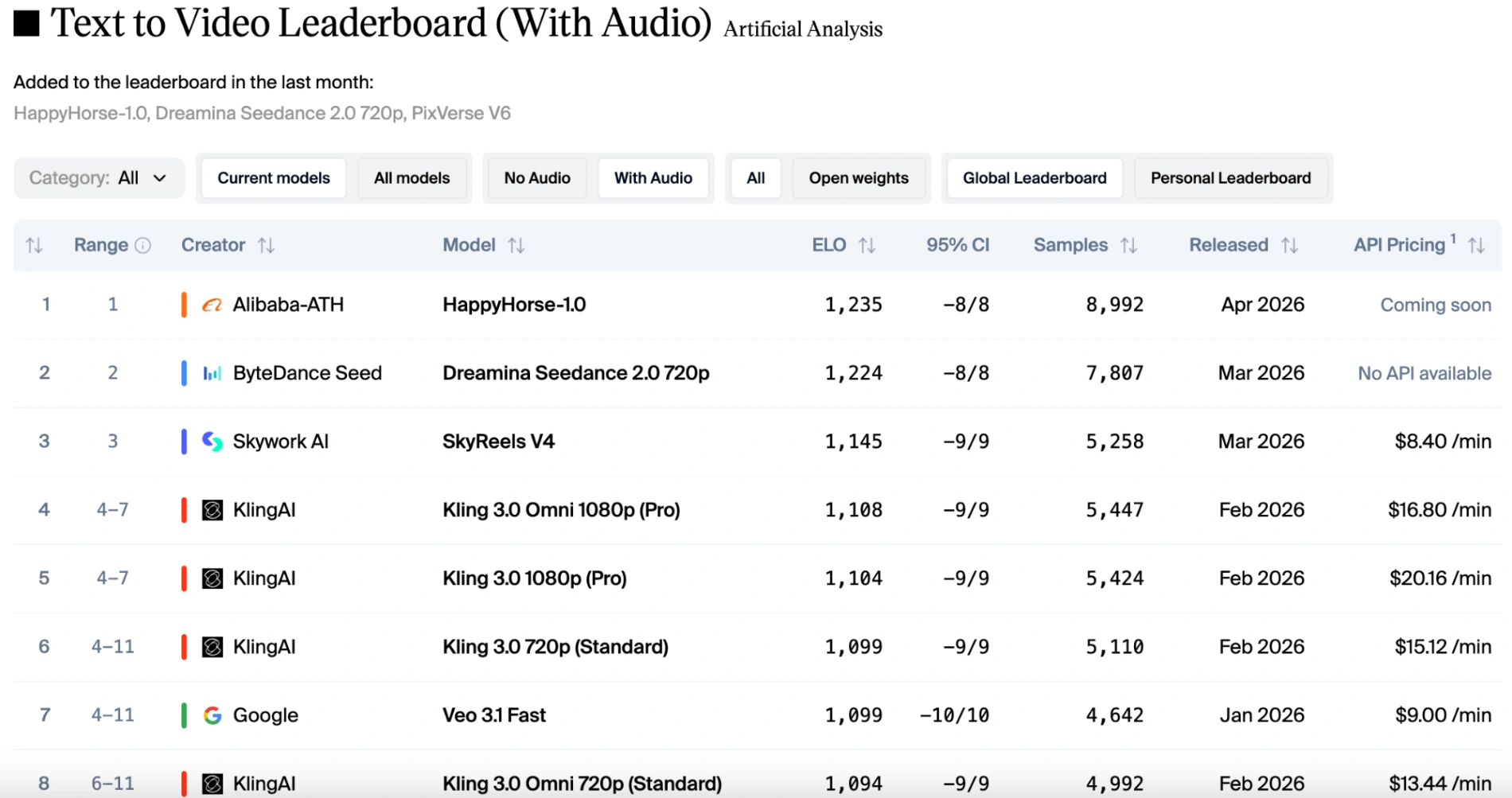
Anche nella categoria da testo a video (con audio), l'ultimo modello di video AI di Alibaba si è classificato primo nelle classifiche Elo, conducendo Dreamina Seedance 2.0 720p di 11 punti.
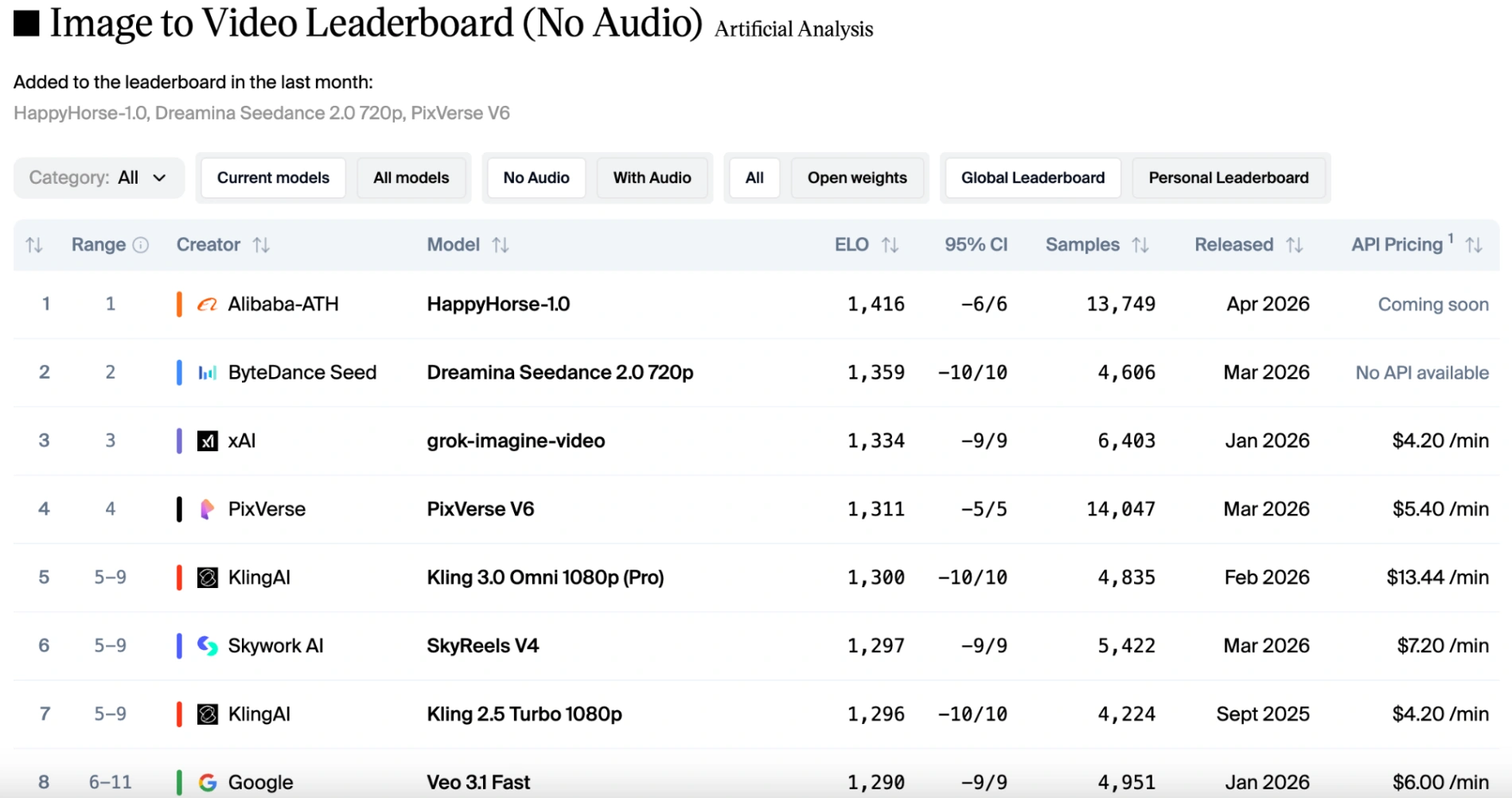
Nella categoria da immagine a video (senza audio), ha raggiunto un punteggio straordinariamente alto di 1416, stabilendo un nuovo record per il modello video di Alibaba su questa classifica.
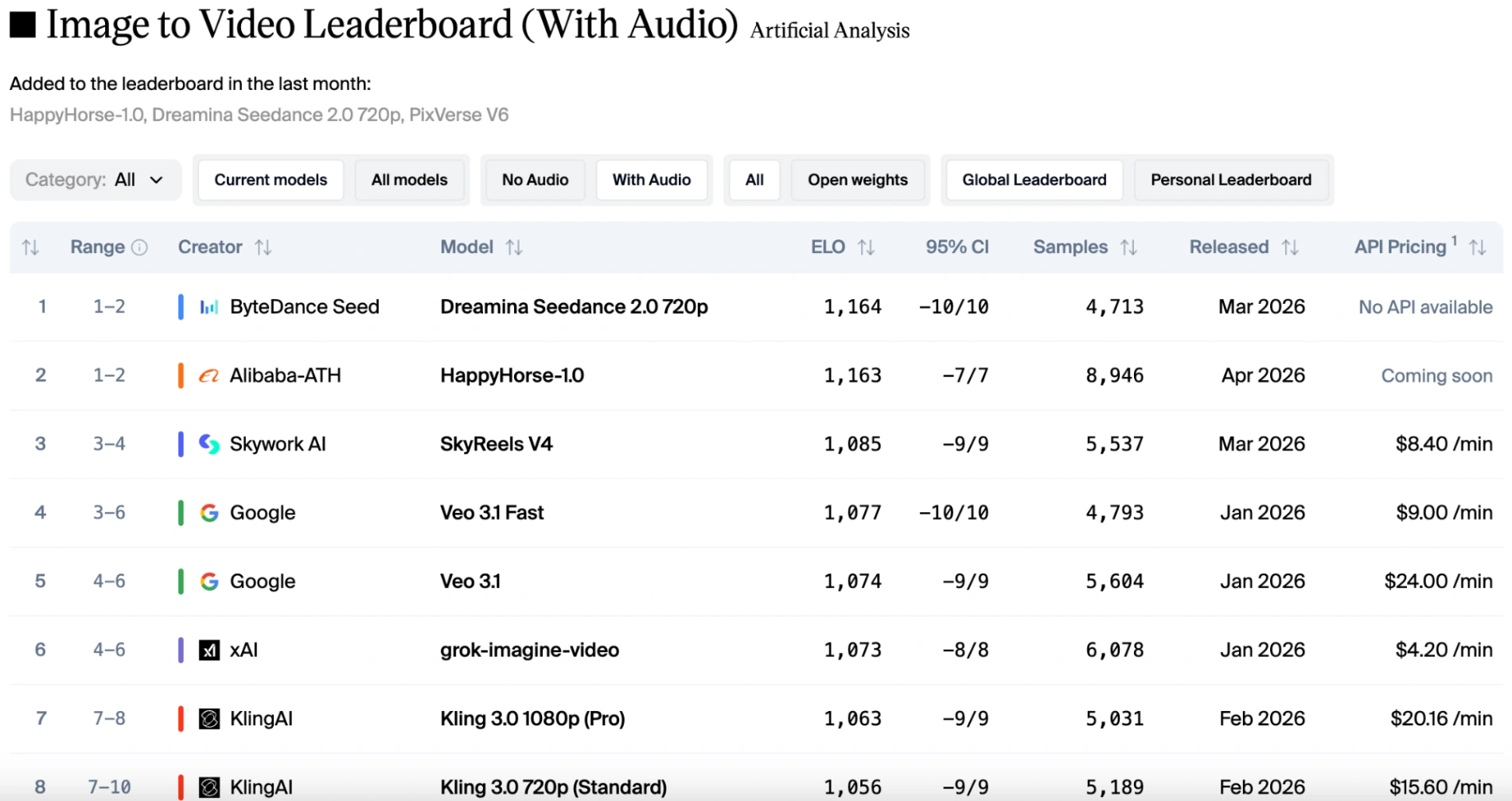
Anche nella traccia audio, che ha requisiti estremamente alti per la coordinazione audiovisiva, questo "cavallo felice" è alla pari con il punteggio Elo di Seedance 2.0.
Prompt: Un corto in stile Pixar su un piccolo cono del traffico nervoso che sogna di essere un pilone del traguardo a una gara importante. Altri coni deridono le sue ambizioni. Un operaio edile lo posiziona accidentalmente al traguardo di una maratona. Il viso dipinto del cono passa dal terrore alla gioia mentre i corridori passano. Il coriandolo cade sulla sua testa a cono. Altri coni guardano in TV, ispirati. Audio: Suoni del traffico che diventano applausi della folla, musica ispiratrice che si gonfia.
Prompt: Una palla da basket che rimbalza su un campo interno vuoto, creando un eco forte e ritmico con ogni colpo contro il pavimento in legno lucidato, punteggiato dal cigolio acuto di scarpe da ginnastica in gomma.
Prompt: Un fascio di torcia che esplora un sistema di grotte, illuminando formazioni di calcare bagnato. La luce cattura depositi di calcite cristallina che brillano e lampeggiano. Dove il fascio passa attraverso acqua stagnante poco profonda, crea pattern caustici luminosi sul fondo sommerso. Stalattiti proiettano lunghe ombre oscillanti mentre la torcia si muove. Audio: Gocciolio d'acqua che echeggia, passi su roccia bagnata, respiro in spazio chiuso.
Prompt: 1.Persona inizia a camminare in avanti naturalmente. Andatura realistica, continua con movimenti fluidi di braccia e testa. Nessuno scivolamento dei piedi. 2.Una torre Jenga massicciamente inclinata. Una mano tremante estrae miracolosamente un blocco centrale. La torre ondeggia ma tiene. Gli spettatori si inclinano indietro, poi esalano con risate di sollievo. Audio: silenzio teso, legno che scivola, collettivo sussulto, risate di sollievo. 3.Animazione in stile Pixar: Una ragazza con lentiggini e capelli rossi ricci selvaggi corre attraverso un prato ventoso di fiori selvatici. Caratteristiche simulazione iper-realistica dei capelli (ricci che rimbalzano indipendentemente, riflessi di luce solare scintillanti, moto secondario naturale quando si ferma). Scattering sottocutaneo caldo sulla pelle. Audio: risate gioiose, vento che soffia, partitura orchestrale edificante.
Creazione di contenuti per social media
I creatori possono produrre video brevi coinvolgenti per piattaforme come TikTok o YouTube Shorts in modo efficiente. Utilizzando il processo di generazione rapido e le funzionalità di audio nativo, gli influencer possono mantenere alte frequenze di pubblicazione riducendo significativamente il tempo di editing audio manuale.
Marketing e spot commerciali di marca
I team pubblicitari possono creare spot commerciali di alta qualità da semplici descrizioni di testo o foto di prodotti. Il supporto nativo per prompt multilingue consente un marketing globale senza soluzione di continuità, permettendo ai team di generare campagne localizzate culturalmente rilevanti facilmente.
Prototipazione per lo sviluppo di giochi
Gli sviluppatori di giochi possono prototipare rapidamente cutscene cinematografiche e animazioni ambientali. Con la sintesi unificata di audio e video, gli studi possono generare audio spaziale sincronizzato insieme alle immagini visive, aiutando a visualizzare l'atmosfera finale del gioco all'inizio del ciclo di sviluppo.
Animazione di arte digitale
Gli artisti digitali possono trasformare illustrazioni statiche o concept art in pezzi in movimento immersivi. Sfruttando le forti capacità da immagine a video del modello, i creatori possono mantenere una coerenza rigorosa dei personaggi e dell'ambiente senza perdere lo stile artistico originale.
Narrazione cinematografica
I filmmaker indipendenti possono semplificare la pre-produzione e la visualizzazione di cortometraggi. Il motore di movimento consapevole della fisica e le capacità precise di sincronizzazione labiale consentono ai registi di creare sequenze narrative complesse con movimenti umani realistici e dialoghi sincronizzati.
Visualizzazione di prodotti per e-commerce
I rivenditori possono elevare i loro negozi online trasformando scatti statici di prodotti in video dinamici di presentazione. Il modello garantisce accuratezza fisica e aggiunge effetti sonori perfettamente abbinati (come lo sfregamento di tessuti o clic meccanici), fornendo un'esperienza virtuale coinvolgente per gli acquirenti online.