

HappyHorse - 알리바바에서 최신 AI 비디오 모델
HappyHorse는 알리바바의 ATH AI 혁신 유닛에서 최신 AI 비디오 모델입니다. HappyHorse-1.0는 Artificial Analysis Video Arena에서 #1위를 차지합니다. 텍스트를 비디오로 및 이미지를 비디오로를 포함한 네 가지 비디오 생성 방식을 모두 지원하며, 각각 내장 오디오 유무에 따라 가능합니다.
통합 오디오 및 비디오 합성
HappyHorse 1.0는 단일 텍스트 프롬프트에서 직접 고품질 비디오와 동기화된 음향 효과를 모두 생성함으로써 창작 과정을 단순화합니다. 통합 Transformer 시퀀스 내에서 비디오 및 오디오 토큰을 처리함으로써, 이 모델은 청각 요소가 화면상의 동작(예: 물결 치는 파도 또는 엔진 소리)과 자연스럽게 정렬되도록 보장하여, 추가 오디오 후처리 필요성을 줄이는 데 도움이 됩니다.

일관된 이미지를 비디오로 애니메이션
정지 이미지를 생생하게 만드는 데 있어, 이 모델은 Artificial Analysis Video Arena에서 강력한 성능을 보여주며, 이미지를 비디오로(오디오 없음) 트랙에서 1416 Elo 점수를 포함합니다. 캐릭터 일관성 유지 및 환경 디테일 보존에 중점을 두어, 컨셉 아트, 초상화 및 제품 사진을 애니메이션화하는 실용적인 옵션이 됩니다.
물리학 인식 모션 모델링
AI 비디오에서 "비자연적", 왜곡된 움직임과 같은 일반적인 시각적 문제를 해결하기 위해, HappyHorse는 실제 물리학을 존중하도록 설계된 최적화된 모션 엔진을 활용합니다. 이는 유연한 인간 보행, 현실적인 유체 역학, 안정적인 카메라 팬을 생성하는 데 도움이 됩니다. 물리적 제약을 이해함으로써, 이 모델은 이전 세대 비디오 도구에서 자주 보이는 뒤틀림 아티팩트를 크게 줄입니다.
내장 다국어 프롬프트 이해
내장 멀티모달 모델로서, HappyHorse는 중간 번역 단계에 의존하지 않고 다국어(영어, 중국어, 일본어 포함)로 프롬프트를 직접 처리합니다. 이를 통해 사용자는 모국어로 문화적으로 특정된 설명을 입력할 수 있어, 원본 텍스트 프롬프트의 정확성과 미묘한 시각적 뉘앙스를 유지하는 데 도움이 됩니다.
효율적인 8단계 생성 과정
기술적 효율성은 HappyHorse 1.0의 주요 초점으로, 단 8개의 노이즈 제거 단계에서 명확한 비디오 출력을 달성합니다. 최적화된 Transformer 아키텍처와 고급 샘플링 기술을 활용함으로써, 이 모델은 1.2배 종단 간 가속을 제공합니다. 이 빠른 생성 과정은 창작자가 아이디어를 테스트하고 프로젝트를 더 편안하게 반복할 수 있도록 합니다.
정확한 립싱크 및 대화 매칭
이 모델은 대화와 캐릭터 입 움직임을 일치시키도록 설계된 전용 립싱크 기능을 통합합니다. "초저 WER"(단어 오류율)을 목표로 함으로써, HappyHorse는 생성된 음성이 시각적 요소와 자연스럽게 정렬되도록 보장합니다. 이 기능은 외부 소프트웨어에서의 수동 타이밍 조정 필요성을 최소화하여 애니메이션 워크플로우를 간소화합니다.
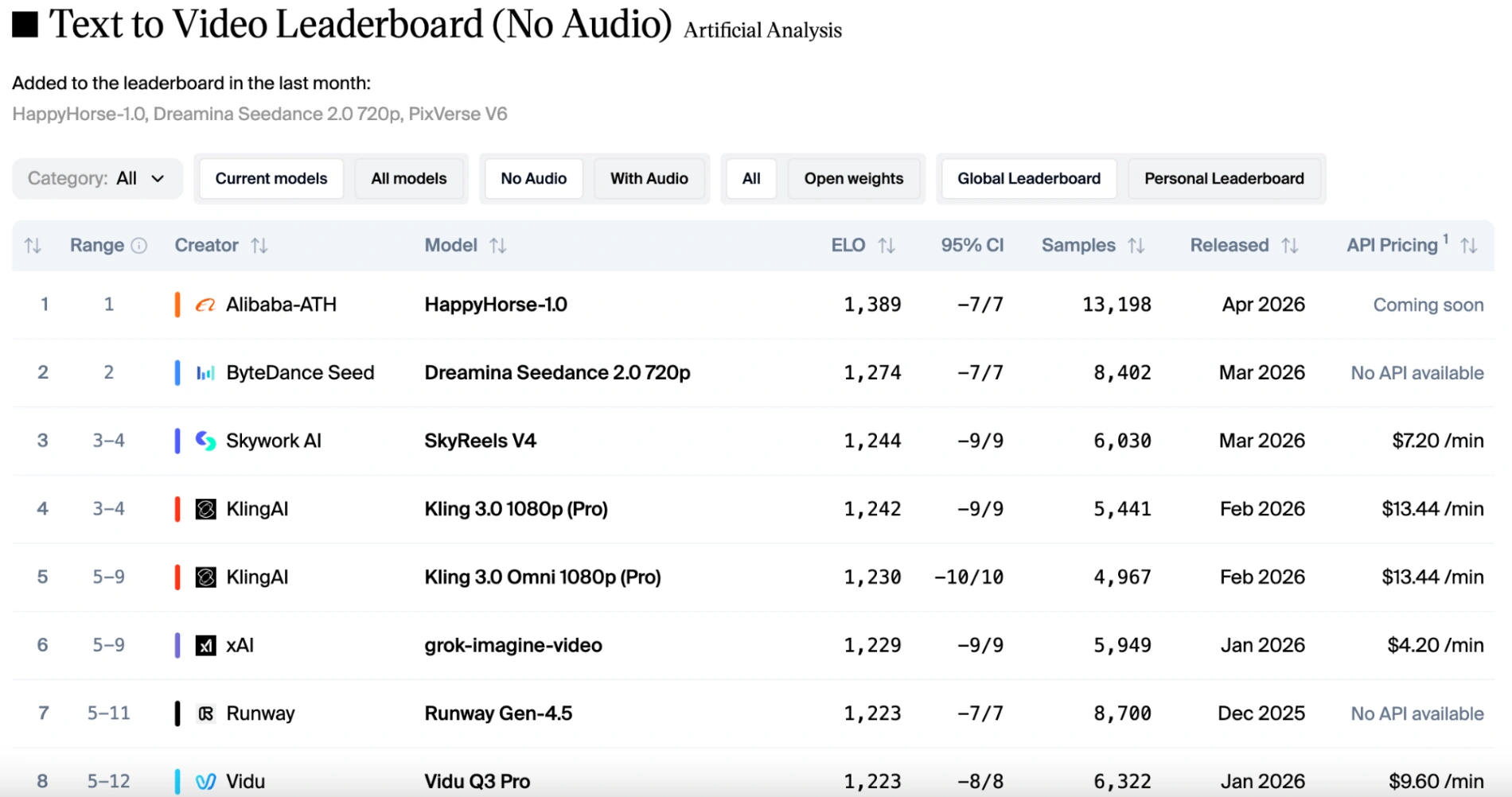
Happy Horse는 텍스트를 비디오로(오디오 없음) 트랙에서 1389 Elo 점수로 1위를 차지했으며, 2위인 Dreamina Seedance 2.0보다 약 115점 앞섭니다.
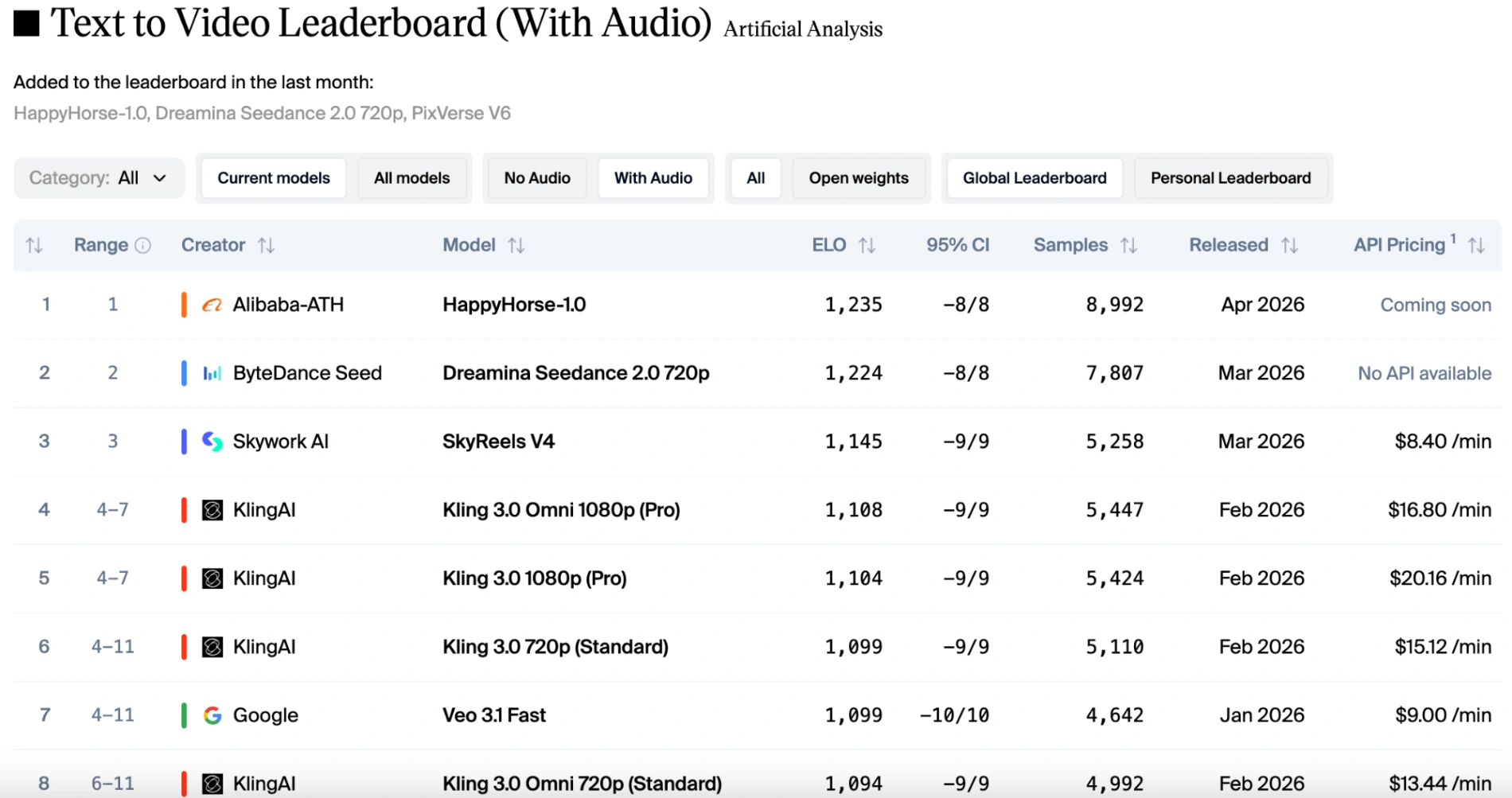
텍스트를 비디오로(오디오 있음) 카테고리에서도 알리바바의 최신 AI 비디오 모델은 Elo 순위에서 1위를 차지했으며, Dreamina Seedance 2.0 720p보다 11점 앞섭니다.
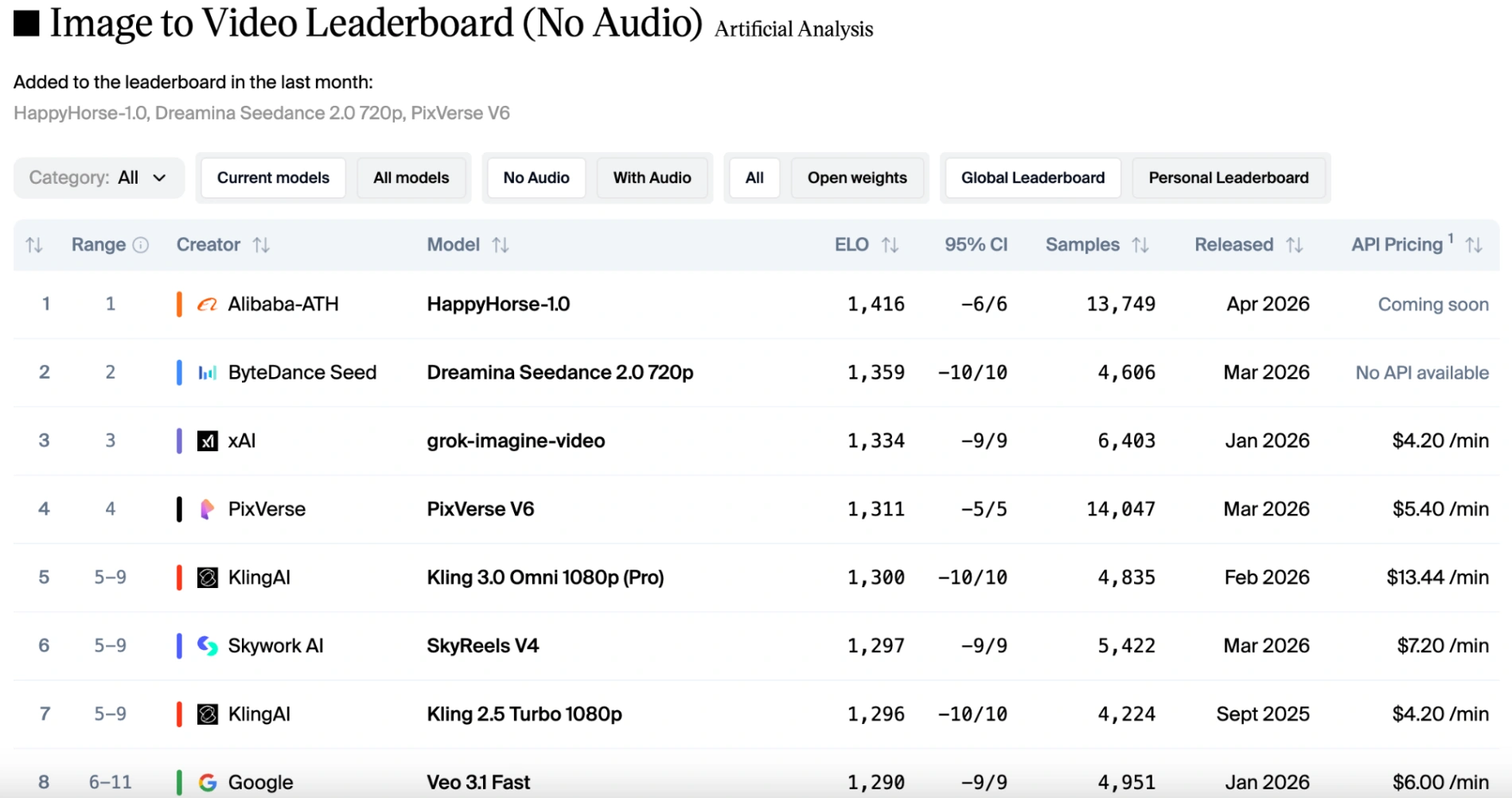
이미지를 비디오로(오디오 없음) 카테고리에서 1416점의 놀라운 높은 점수를 달성하여, 이 리더보드에서 알리바바의 비디오 모델에 대한 새로운 기록을 세웠습니다.
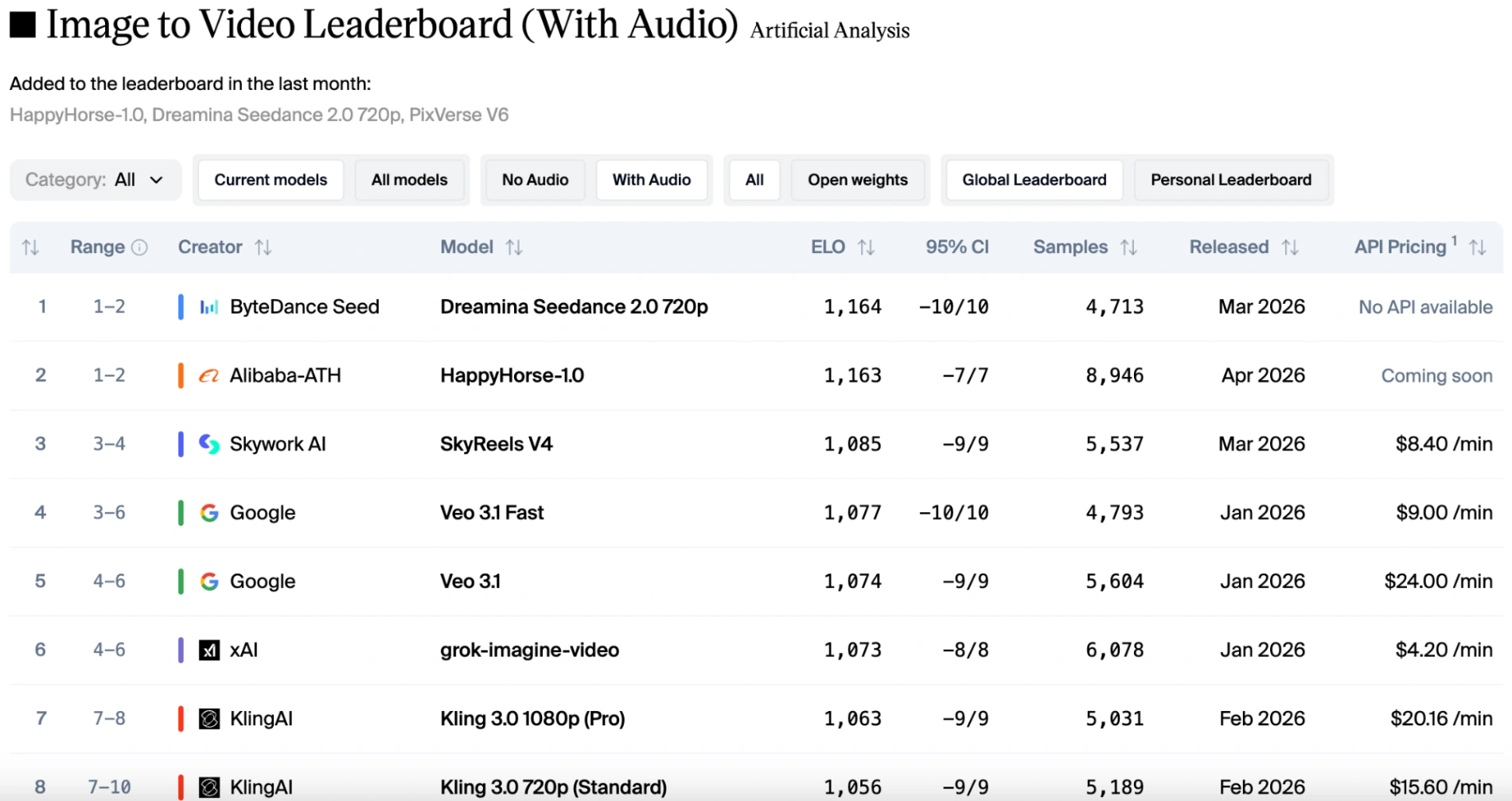
시청각 조화에 매우 높은 요구사항이 있는 오디오 트랙에서도 이 "해피 호스"는 Seedance 2.0의 Elo 점수와 동등합니다.
프롬프트: 큰 경주의 결승선 폴이 되고 싶어하는 긴장한 작은 트래픽 콘에 관한 픽사 스타일 단편. 다른 콘들이 그 야망을 비웃습니다. 건설 노동자가 실수로 마라톤 결승선에 그것을 놓습니다. 콘의 그려진 얼굴이 공포에서 기쁨으로 바뀌며 달리는 사람들이 지나갑니다. 콘 머리 위에 색종이가 떨어집니다. 다른 콘들이 TV에서 보고 감동받습니다. 오디오: 교통 소리가 군중의 환호 소리로 변하고, 감동적인 음악이 커집니다.
프롬프트: 빈 실내 코트에서 튀는 농구공, 매번 광택 나는 하드우드 바닥에 부딪힐 때마다 크고 리드미컬한 메아리를 내며, 고무 운동화의 날카로운 삐걱거리는 소리가 중간에 끼어듭니다.
프롬프트: 동굴 시스템을 탐사하는 손전등 빛, 젖은 석회암 구조물을 비춥니다. 빛이 반짝이고 번쩍이는 결정질 칼사이트 퇴적물을 포착합니다. 빛이 얕은 고인 물을 통과할 때, 잠긴 바닥에 밝은 카우스틱 패턴을 만듭니다. 손전등이 움직일 때 종유석이 길고 흔들리는 그림자를 던집니다. 오디오: 물방울 소리 메아리, 젖은 바위 위 발자국 소리, 제한된 공간에서의 숨소리.
프롬프트: 1.사람이 자연스럽게 앞으로 걷기 시작합니다. 현실적이고 연속적인 보행으로 부드러운 팔과 머리 움직임. 발 미끄러짐 없음. 2.크게 기울어진 젠가 탑. 떨리는 손이 기적적으로 중간 블록을 빼냅니다. 탑이 흔들리지만 버틸니다. 구경꾼들이 뒤로 몸을 기울이다가 안도한 웃음과 함께 숨을 내쉽니다. 오디오: 긴장된 침묵, 나무 미끄러짐 소리, 집단적 숨막힘, 안도한 웃음. 3.픽사 스타일 애니메이션: 거칠게 곱슬진 빨간 머리에 주근깨가 있는 소녀가 바람 부는 야생화 목초지를 달립니다. 초현실적인 머리카락 시뮬레이션 기능(독립적인 튀는 곱슬머리, 반짝이는 햇빛 하이라이트, 그녀가 멈출 때 자연스러운 2차 동작). 피부에 따뜻한 피하 산란. 오디오: 기쁜 웃음소리, 쌩쌩 부는 바람 소리, 고양되는 오케스트라 점수.
소셜 미디어 콘텐츠 제작
창작자는 TikTok 또는 YouTube Shorts와 같은 플랫폼을 위해 매력적인 짧은 비디오를 효율적으로 제작할 수 있습니다. 빠른 생성 과정 및 내장 오디오 기능을 활용함으로써, 인플루언서는 높은 게시 빈도를 유지하면서 수동 오디오 편집 시간을 크게 줄일 수 있습니다.
마케팅 및 브랜드 광고
광고 팀은 간단한 텍스트 설명 또는 제품 사진에서 고품질 브랜드 광고를 생성할 수 있습니다. 내장 다국어 프롬프트 지원은 원활한 글로벌 마케팅을 가능하게 하여, 팀이 문화적으로 적합한 지역화 캠페인을 쉽게 생성할 수 있게 합니다.
게임 개발 프로토타이핑
게임 개발자는 시네마틱 컷신 및 환경 애니메이션을 빠르게 프로토타이핑할 수 있습니다. 통합 오디오 및 비디오 합성으로, 스튜디오는 시각적 요소와 동기화된 공간 오디오를 생성하여 개발 주기 초기에 최종 게임 분위기를 시각화하는 데 도움이 됩니다.
디지털 아트 애니메이션
디지털 아티스트는 정적 일러스트레이션이나 컨셉 아트를 몰입감 있는 움직이는 작품으로 변환할 수 있습니다. 이 모델의 강력한 이미지를 비디오로 기능을 활용함으로써, 창작자는 원본 예술적 스타일을 잃지 않고 엄격한 캐릭터 및 환경 일관성을 유지할 수 있습니다.
시네마틱 내러티브 스토리텔링
독립 영화 제작자는 단편 영화의 사전 제작 및 시각화를 간소화할 수 있습니다. 물리학 인식 모션 엔진과 정밀한 립싱크 기능으로, 감독은 현실적인 인간 움직임과 동기화된 대화를 포함한 복잡한 내러티브 시퀀스를 생성할 수 있습니다.
전자상거래 제품 시각화
소매업체는 정적 제품 사진을 동적 쇼케이스 비디오로 전환하여 온라인 매장을 고양시킬 수 있습니다. 이 모델은 물리적 정확성을 보장하고 완벽하게 매칭된 음향 효과(예: 옷 스치는 소리 또는 기계적 클릭 소리)를 추가하여 온라인 쇼핑객을 위한 매력적인 가상 경험을 제공합니다.