

HappyHorse: El último modelo de video de IA de Alibaba
HappyHorse es el último modelo de video de IA de la Unidad de Innovación de IA ATH de Alibaba. HappyHorse-1.0 ocupa el puesto #1 en Artificial Analysis Video Arena. Soporta las cuatro modalidades de generación de video: Texto a Video e Imagen a Video, cada una con y sin audio nativo.
Síntesis unificada de audio y video
HappyHorse 1.0 simplifica el proceso creativo al generar tanto video de alta calidad como efectos de sonido sincronizados directamente desde un solo prompt de texto. Al procesar tokens de video y audio dentro de una secuencia Transformer unificada, el modelo garantiza que los elementos auditivos se alineen naturalmente con las acciones en pantalla (como una ola que salpica o ruido de motor), lo que ayuda a reducir la necesidad de postproducción de audio adicional.

Animación consistente de imagen a video
Para dar vida a imágenes estáticas, este modelo demuestra un fuerte rendimiento en Artificial Analysis Video Arena, incluyendo una puntuación Elo notable de 1416 en la pista de imagen a video (sin audio). Se centra en mantener la consistencia de los personajes y preservar los detalles ambientales, convirtiéndolo en una opción práctica para animar arte conceptual, retratos y fotos de productos.
Modelado de movimiento consciente de la física
Para abordar problemas visuales comunes como movimientos 'antinaturales' y distorsionados en video de IA, HappyHorse utiliza un motor de movimiento optimizado diseñado para respetar la física del mundo real. Esto ayuda a producir pasos humanos fluidos, dinámica de fluidos realista y paneos de cámara estables. Al comprender las restricciones físicas, el modelo reduce significativamente los artefactos de deformación a menudo vistos en generaciones anteriores de herramientas de video.
Comprensión nativa de prompts multilingües
Como modelo multimodal nativo, HappyHorse procesa directamente prompts en múltiples idiomas (incluyendo inglés, chino y japonés) sin depender de pasos de traducción intermedios. Esto permite a los usuarios ingresar descripciones culturalmente específicas en su idioma nativo, ayudando a mantener la precisión y los matices visuales sutiles del prompt de texto original.
Proceso eficiente de generación en 8 pasos
La eficiencia técnica es un enfoque clave para HappyHorse 1.0, que logra salidas de video claras en solo 8 pasos de denoising. Al aprovechar una arquitectura Transformer optimizada y técnicas de muestreo avanzadas, el modelo ofrece una aceleración de extremo a extremo de 1.2x. Este proceso de generación más rápido permite a los creadores probar ideas e iterar en sus proyectos de manera más cómoda.
Sincronización precisa de labios y coincidencia de diálogo
El modelo integra capacidades dedicadas de sincronización de labios diseñadas para igualar el diálogo hablado con los movimientos de la boca del personaje. Al apuntar a un 'WER ultra bajo' (Tasa de Error de Palabras), HappyHorse garantiza que el habla generada se alinee naturalmente con los elementos visuales. Esta característica agiliza el flujo de trabajo de animación al minimizar la necesidad de ajustes manuales de tiempo en software externo.
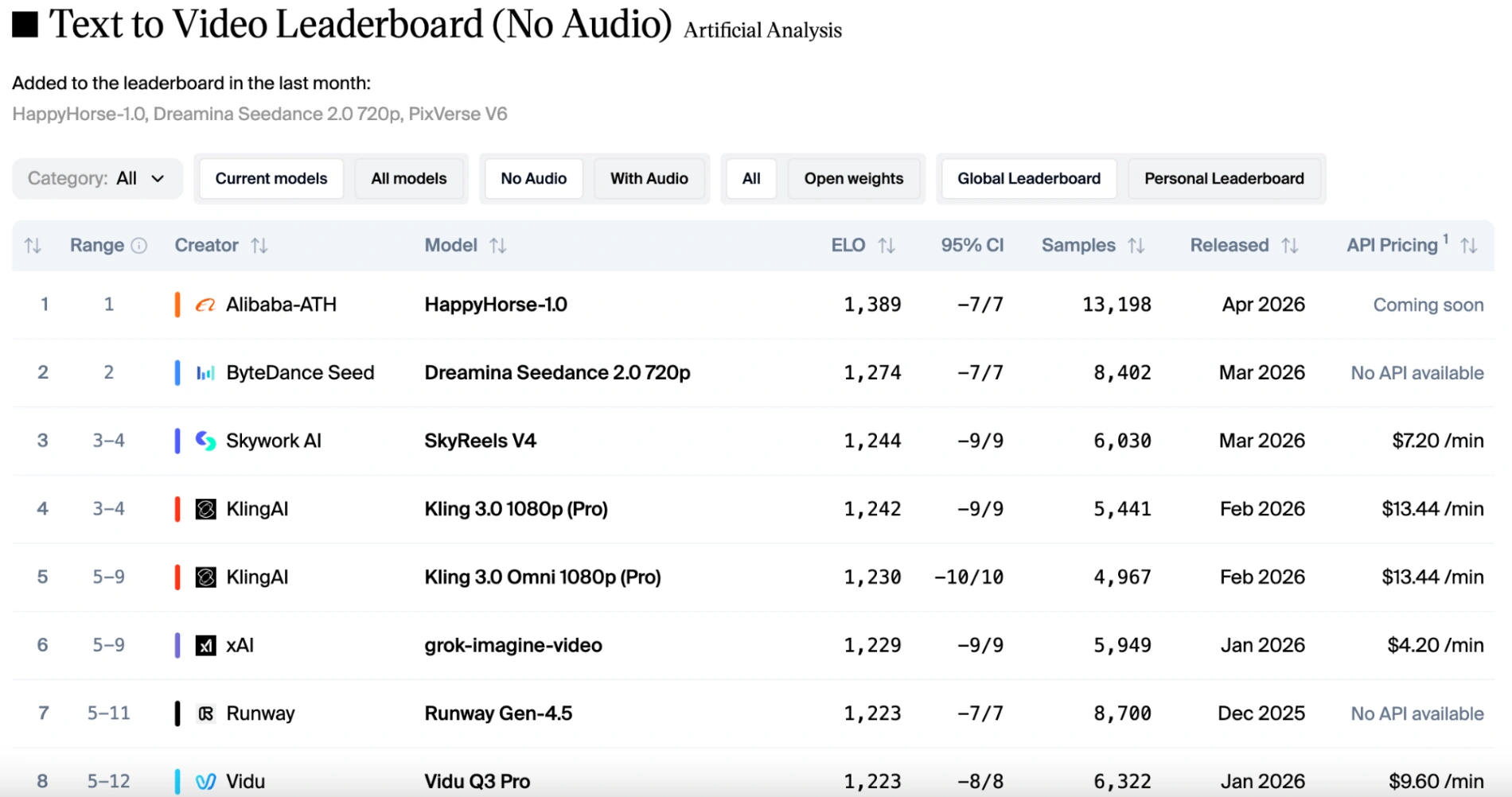
Happy Horse ocupó el primer lugar en la pista de texto a video (sin audio) con 1389 puntos Elo, dejando al segundo lugar, Dreamina Seedance 2.0, por casi 115 puntos.
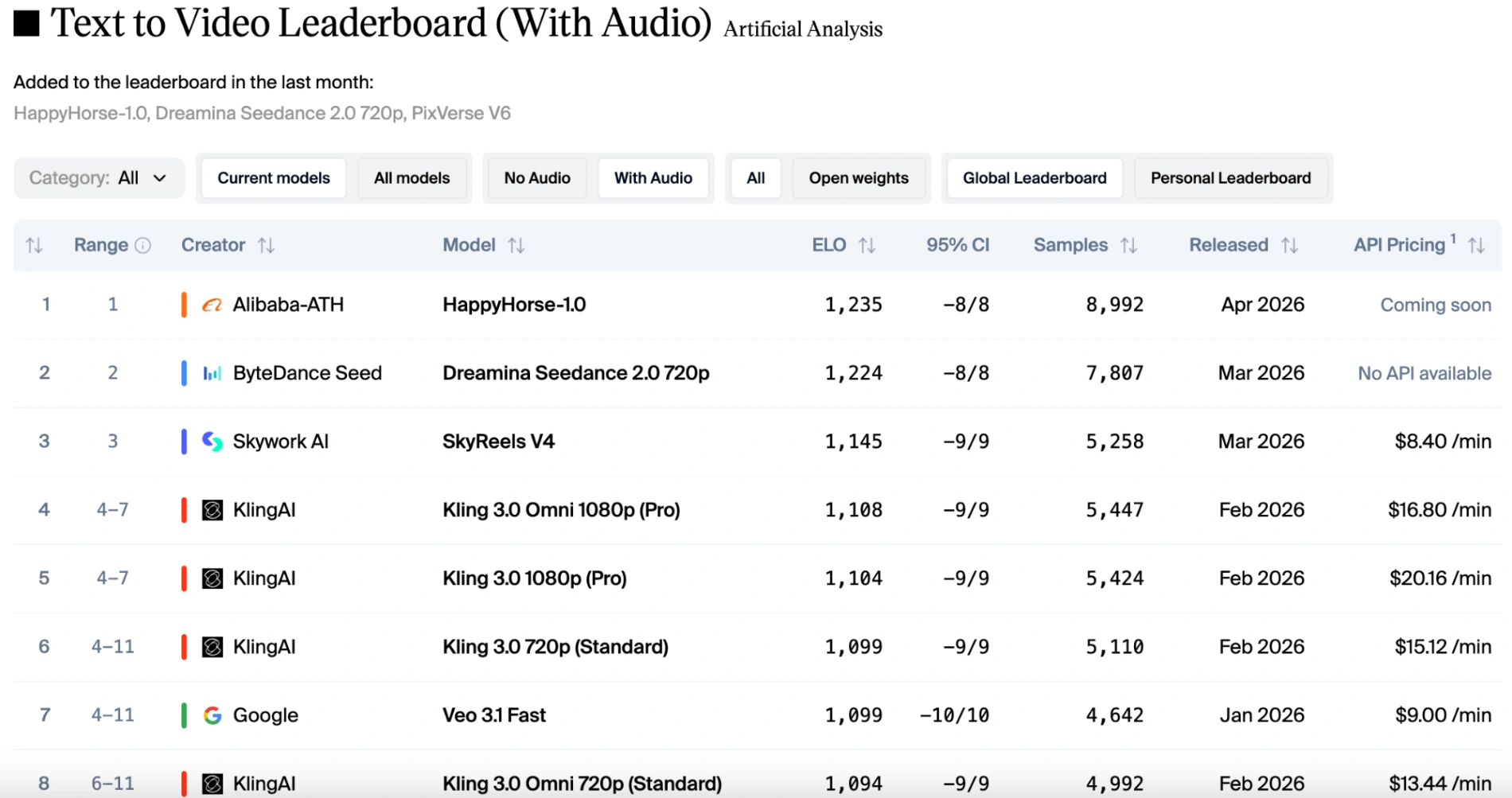
Incluso en la categoría de texto a video (con audio), el último modelo de video de IA de Alibaba ocupó el primer lugar en las clasificaciones Elo, liderando a Dreamina Seedance 2.0 720p por 11 puntos.
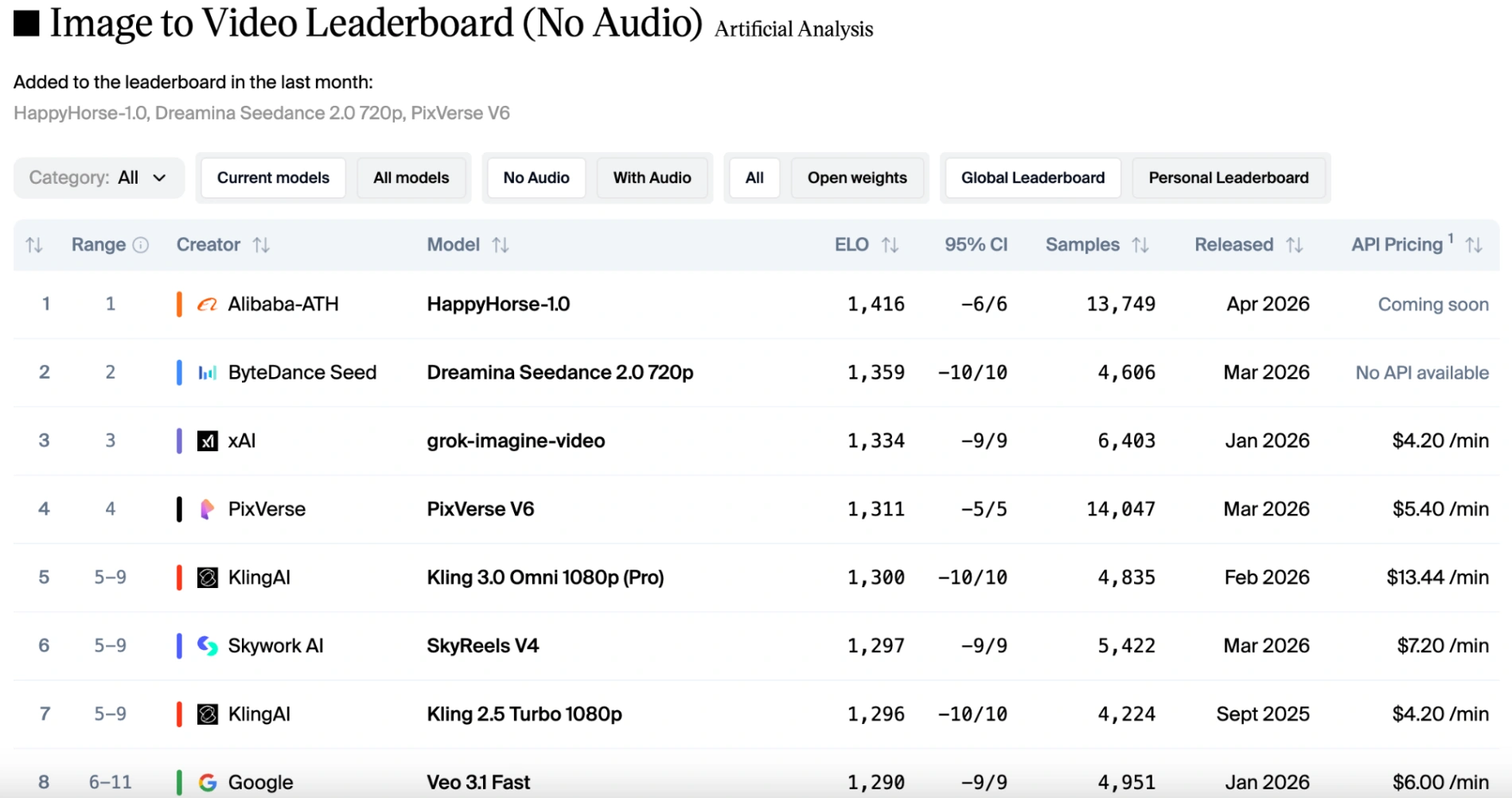
En la categoría de imagen a video (sin audio), logró una puntuación asombrosamente alta de 1416, estableciendo un nuevo récord para el modelo de video de Alibaba en esta tabla de clasificación.
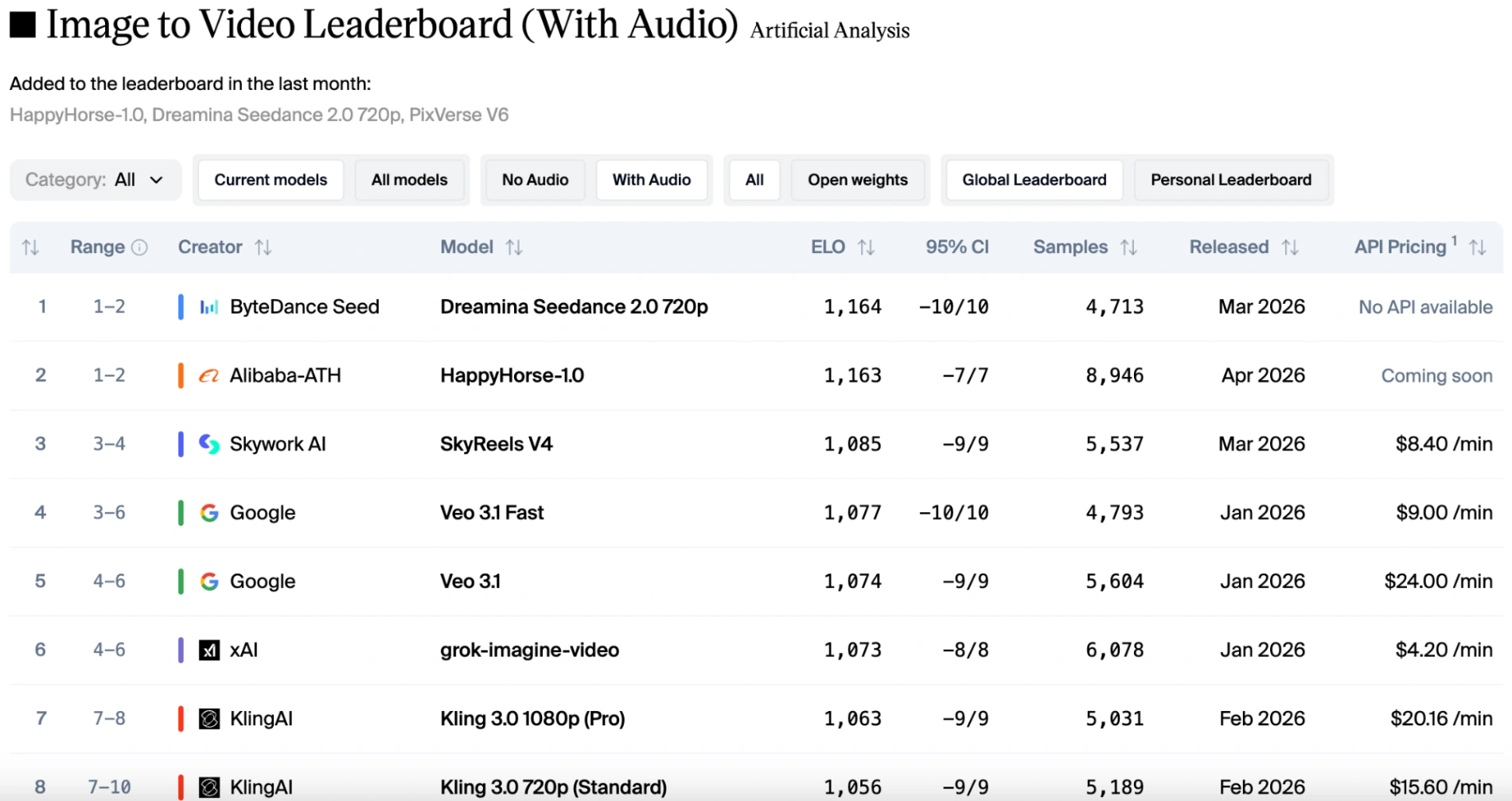
Incluso en la pista de audio, que tiene requisitos extremadamente altos para la coordinación audiovisual, este 'caballo feliz' está a la par con la puntuación Elo de Seedance 2.0.
Prompt: Un corto estilo Pixar sobre un pequeño cono de tráfico nervioso que sueña con ser un cono de meta en una carrera importante. Otros conos se burlan de sus ambiciones. Un trabajador de la construcción lo coloca accidentalmente en la línea de meta de un maratón. La cara pintada del cono cambia del terror a la alegría mientras los corredores pasan. Confeti cae sobre su cabeza de cono. Otros conos miran en la televisión, inspirados. Audio: Sonidos de tráfico que se convierten en vítores de la multitud, música inspiradora que se intensifica.
Prompt: Un balón de baloncesto rebotando en una cancha interior vacía, creando un eco fuerte y rítmico con cada golpe contra el suelo de madera pulida, interrumpido por el chirrido agudo de zapatillas de goma.
Prompt: Un haz de linterna explorando un sistema de cuevas, iluminando formaciones de piedra caliza húmeda. La luz captura depósitos cristalinos de calcita que brillan y destellan. Donde el haz pasa a través de agua estancada poco profunda, crea patrones de cáustica brillantes en el suelo sumergido. Estalactitas proyectan sombras largas y oscilantes a medida que la linterna se mueve. Audio: Goteo de agua que hace eco, pasos sobre roca húmeda, respiración en un espacio cerrado.
Prompt: 1. Una persona comienza a caminar hacia adelante de forma natural. Paso realista y continuo con movimientos suaves de brazos y cabeza. Sin deslizamiento de pies. 2. Una torre de Jenga inclinada masivamente. Una mano temblorosa extrae milagrosamente un bloque del medio. La torre se balancea pero se mantiene. Los espectadores se inclinan hacia atrás, luego exhalan con risas aliviadas. Audio: Silencio tenso, madera deslizándose, suspiro colectivo, risas aliviadas. 3. Animación estilo Pixar: Una chica con pecas y cabello rojo rizado salvaje corre a través de un campo de flores silvestres con viento. Características simulación de cabello hiperrealista (rizos que rebotan independientemente, reflejos de luz solar brillantes, movimiento secundario natural cuando se detiene). Dispersión subsuperficial cálida en la piel. Audio: Risa alegre, viento rápido, partitura orquestal edificante.
Creación de contenido para redes sociales
Los creadores pueden producir videos cortos atractivos para plataformas como TikTok o YouTube Shorts de manera eficiente. Al utilizar el proceso de generación rápida y las funciones de audio nativo, los influencers pueden mantener altas frecuencias de publicación mientras reducen significativamente el tiempo de edición de audio manual.
Marketing y comerciales de marca
Los equipos de publicidad pueden crear comerciales de marca de alta calidad a partir de simples descripciones de texto o fotos de productos. El soporte nativo de prompts multilingües permite un marketing global sin problemas, permitiendo a los equipos generar campañas localizadas culturalmente relevantes fácilmente.
Prototipado de desarrollo de juegos
Los desarrolladores de juegos pueden prototipar rápidamente escenas cinemáticas y animaciones ambientales. Con la síntesis unificada de audio y video, los estudios pueden generar audio espacial sincronizado junto con los elementos visuales, ayudando a visualizar la atmósfera final del juego temprano en el ciclo de desarrollo.
Animación de arte digital
Los artistas digitales pueden transformar ilustraciones estáticas o arte conceptual en piezas en movimiento inmersivas. Aprovechando las fuertes capacidades de imagen a video del modelo, los creadores pueden mantener una consistencia estricta de personajes y entorno sin perder el estilo artístico original.
Narrativa cinematográfica
Los cineastas independientes pueden agilizar la preproducción y visualización de cortometrajes. El motor de movimiento consciente de la física y las capacidades precisas de sincronización de labios permiten a los directores crear secuencias narrativas complejas con movimientos humanos realistas y diálogo sincronizado.
Visualización de productos de comercio electrónico
Los minoristas pueden elevar sus tiendas en línea convirtiendo fotos estáticas de productos en videos de exhibición dinámicos. El modelo garantiza precisión física y agrega efectos de sonido perfectamente igualados (como el crujido de tela o clics mecánicos), proporcionando una experiencia virtual atractiva para los compradores en línea.