
HappyHorse 1.0 与 Seedance 2.0:哪款 AI 视频模型胜出?
在快速发展的 AI 视频生成领域,两个突出的模型最近吸引了创作者、开发者和视频专业人士的注意。HappyHorse 1.0 和 Seedance 2.0 代表了将文本提示和图像转换为动态视频内容的完全不同的方法。作为一群致力于探索前沿 AI 视频模型的技术专家,我们分析了跨公共基准和实际工作流程的大量数据,为您带来这份全面的评测。
无论您专注于短片叙事还是复杂的多模态制作,理解这些模型各自的优势可以帮助指导您的下一个创意项目。让我们以友好而客观的方式,深入探讨它们的架构、功能和实际应用。
技术架构:引擎盖下的动力源泉
要真正理解这些模型的独特之处,我们首先必须审视它们的底层工程。它们的结构差异直接影响生成速度、输出稳定性和视觉连贯性。
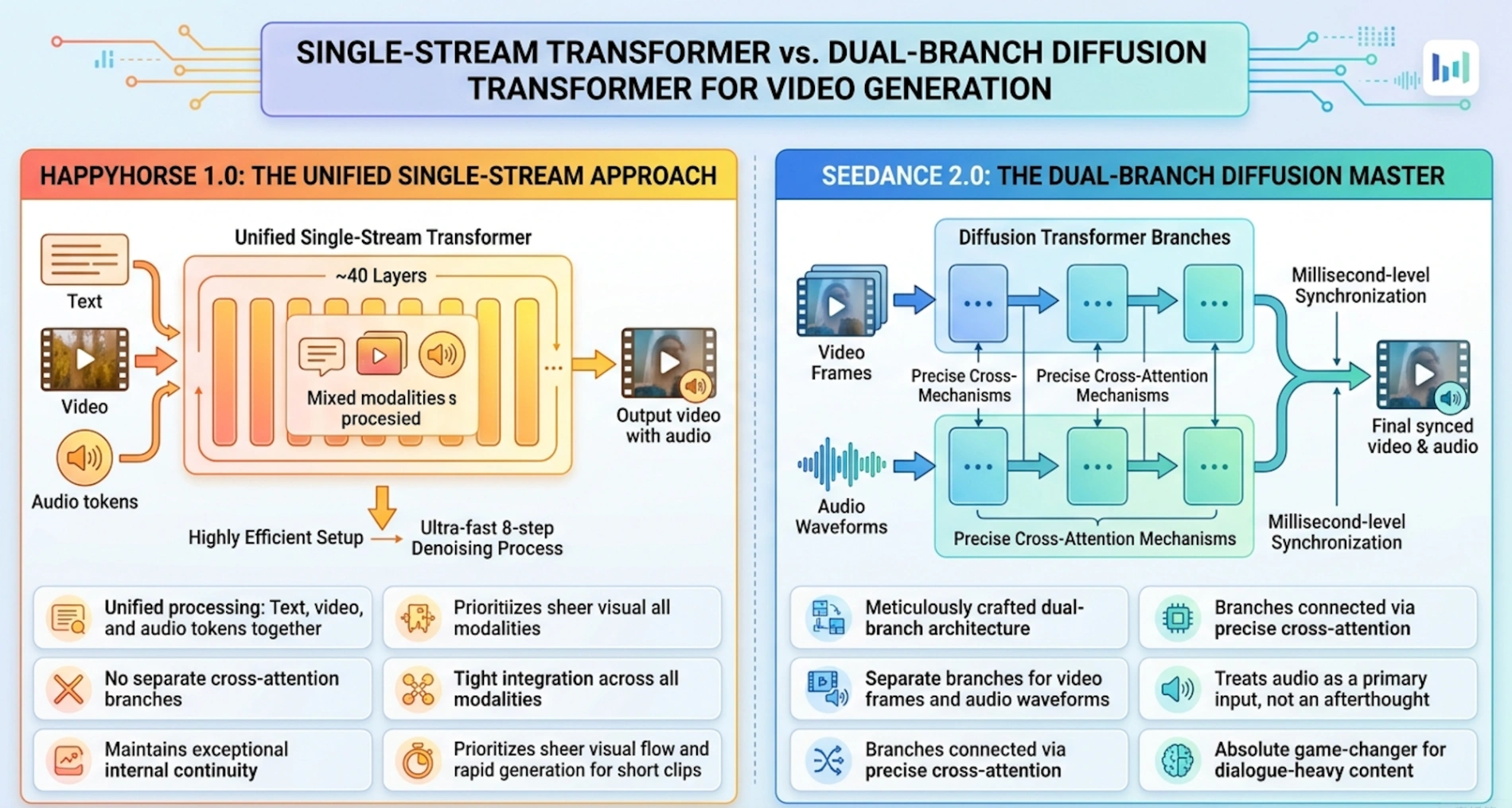
HappyHorse 1.0:统一单流方法 行业分析表明,HappyHorse 1.0 使用了一个包含约 40 层的统一单流 Transformer 架构。在这种高效的设置中,文本、视频和音频词元在一个连续序列中一起处理,不依赖单独的多头交叉注意力分支。这使得模型能够在所有模态之间保持卓越的内部连续性和紧密集成。结合超快的 8 步去噪过程,这种单流方法优先考虑纯粹视觉流程和短片段的快速生成。
Seedance 2.0:双分支扩散大师 相反,Seedance 2.0(由字节跳动知名研究团队开发)依赖于一个精心设计的双分支扩散 Transformer 架构。一个分支专门处理视频帧,另一个管理音频波形。这些分支通过精确的交叉注意力机制连接。通过将音频视为主要输入而非事后添加,这种设置确保了毫秒级的同步。对于制作对话密集型内容的创作者来说,这种双分支方法绝对是一个改变游戏规则的因素。
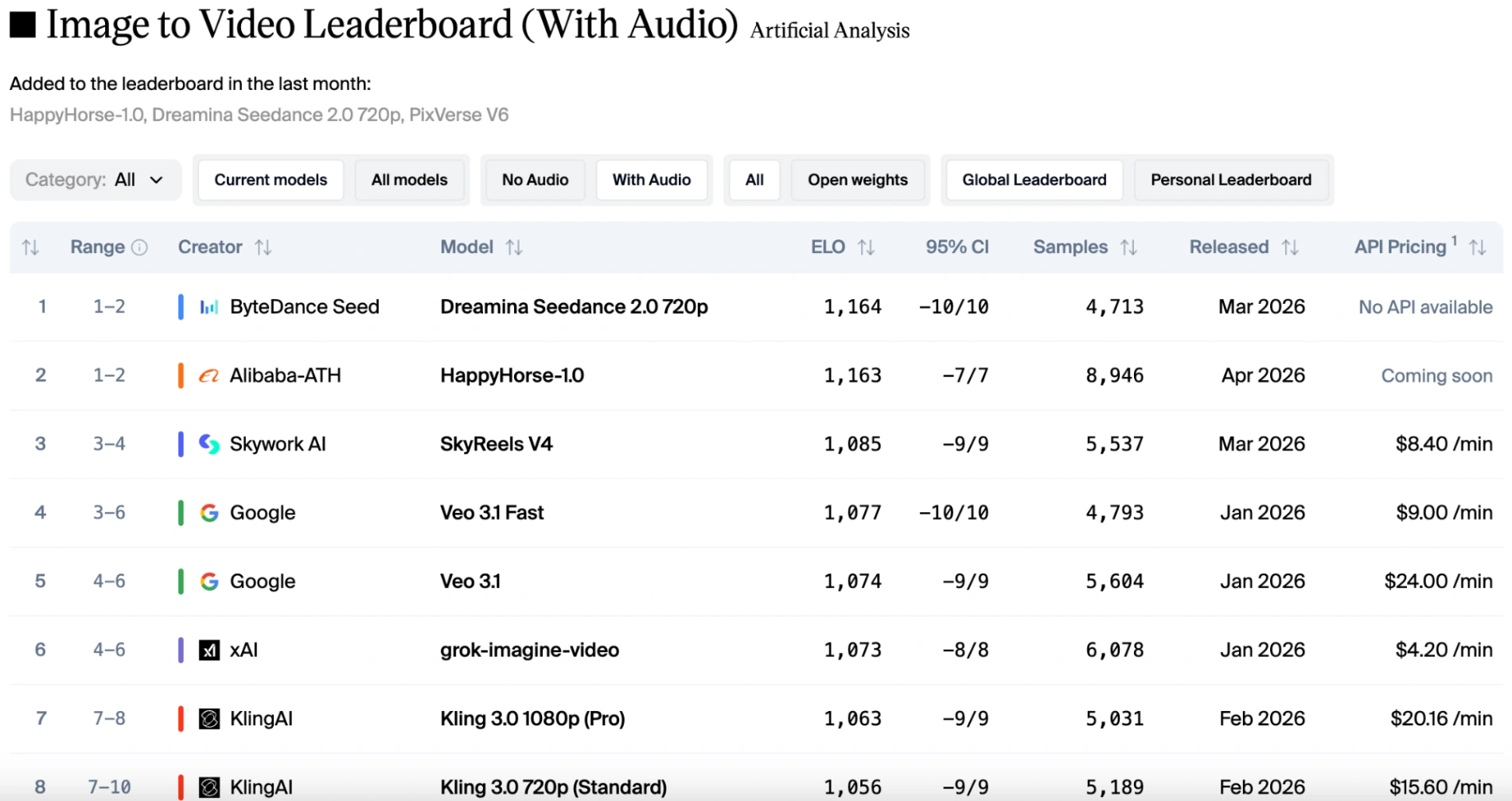
视觉效果与音频:排行榜揭示了什么
公开排行榜,例如 Artificial Analysis Video Arena,提供了极好的盲测洞察,反映了人类偏好。数据揭示了一个有趣的故事,即赢家完全取决于是否包含声音。
在纯视觉类别(文本转视频和图像转视频,不含音频)中,HappyHorse 1.0 保持领先地位。它始终以 50 到 100 Elo 分的优势胜过 Seedance 2.0。投票者绝大多数偏爱 HappyHorse 的自然镜头漂移、锐利的电影细节以及保留参考图像中主体身份的能力。
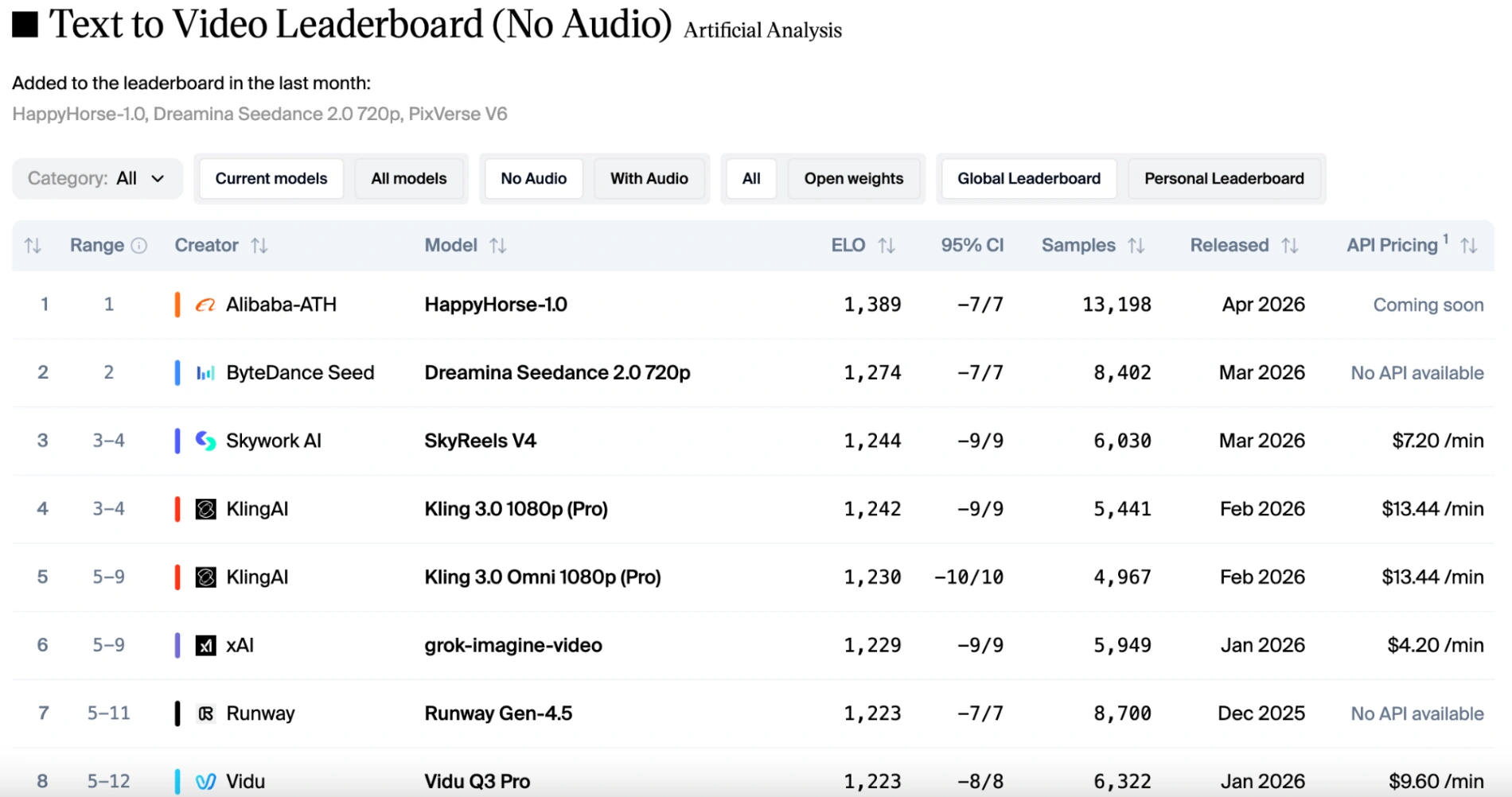
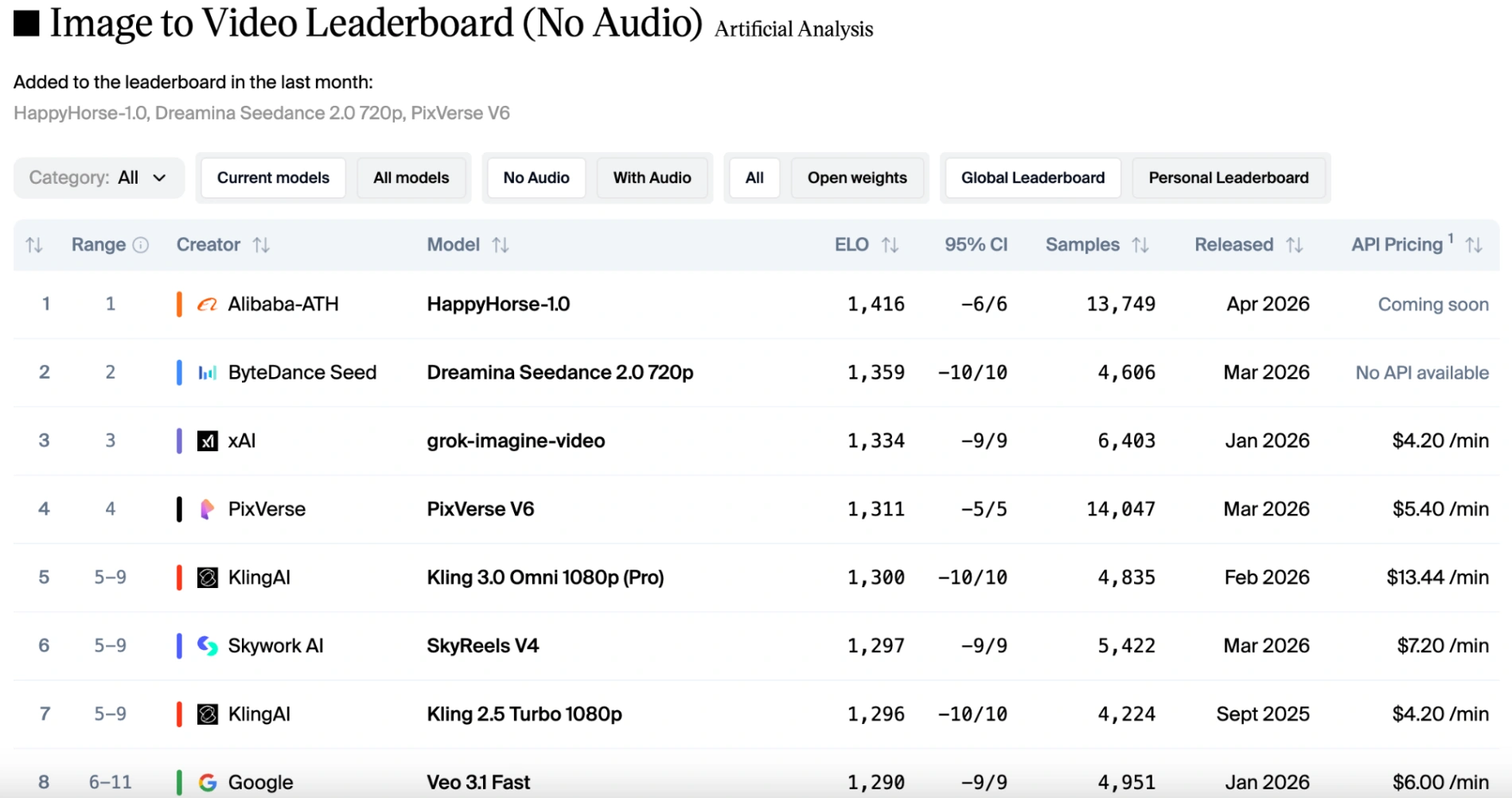
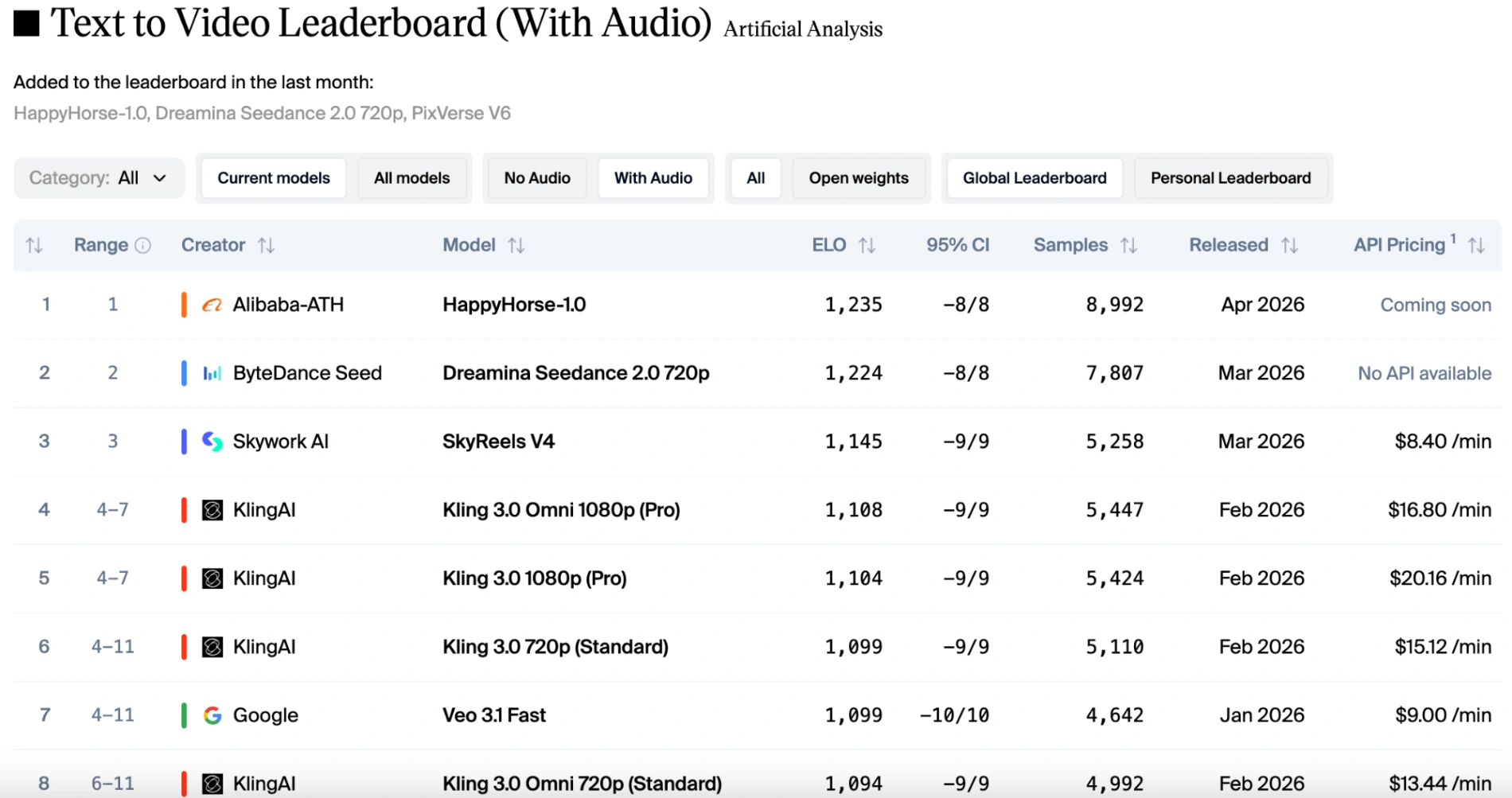
然而,如果将音频因素考虑在内,排名会略微变化。HappyHorse 1.0 仍然在图像转视频(不含音频)中保持第一,Seedance 2.0 在图像转视频(含音频)中夺回榜首,但 HappyHorse 仅落后一分,几乎旗鼓相当。得益于 Seedance 2.0 的原生多模态能力,它提供稳定的运动与完美同步的音效和对话。虽然 HappyHorse 1.0 保持竞争力并支持多种语言,但在复杂的视听和谐是主要评判标准时,它略微落后于 Seedance。
功能比较:输入、输出和控件
并列查看它们的核心功能,突出显示了这些模型如何迎合完全不同的制作风格。
HappyHorse 1.0 对于快速输出非常实用和制作友好。它支持清晰的 720p 和 1080p 分辨率,提供 3 到 15 秒的预设生成时长。创作者会喜欢其灵活的宽高比(包括 16:9,9:16 和 1:1),非常适合社交媒体活动或移动广告。它的图像转视频转换非常强大,允许用户无缝动画化概念艺术。
另一方面,Seedance 2.0 像一个全面的“导演工作站”一样运作。它将界限推至支持高达 2K 的分辨率。真正使其与众不同的是其庞大的输入容量。在单个提示中,用户可以最多提供 9 张参考图像、3 个视频片段和 3 个音频片段。这使得创作者能够以无与伦比的精度控制光照、角色一致性和相机运动。
下面是一个简洁的比较表,总结它们的核心特性:
| 特性 | HappyHorse 1.0 | Seedance 2.0 |
|---|---|---|
| 模型提供商 | 阿里巴巴(中国) | 字节跳动(中国) |
| 主要架构 | 统一单流 Transformer | 双分支扩散 Transformer |
| 核心优势 | 原始视觉连贯性和流畅的图像转视频 | 多模态输入和精确的音频同步 |
| 最大分辨率 | 1080p 电影级 | 高达 2K(取决于配置) |
| 输入灵活性 | 文本、图像(非常强大的图像转视频) | 文本、图像(最多 9 张)、视频(最多 3 个)、音频(最多 3 个) |
| 输出时长 | 支持从 3 到 15 秒的视频时长 | 灵活的连续生成,从 1 到 15 秒 |
| 支持宽高比 | 16:9, 9:16, 1:1, 4:3, 3:4 | 支持多种格式(21:9, 16:9, 4:3, 1:1, 3:4, 9:16) |
| 音频集成 | 可选的附加组件,支持多语言(英语、中文、日语、韩语、德语和法语) | 原生联合生成,音素级口型同步,支持超过 8 种语言 |
| 发布状态 | 于 2026 年 4 月 27 日发布。 | 已发布。API 访问现已完全开放。 |
实际应用场景:你应该选择哪一个?
选择正确的工具最终取决于你创意工作流程的具体需求。没有一个模型适合所有场景,理解它们的实际权衡至关重要。
当使用 HappyHorse 1.0 时: 如果你的项目从经过批准的静态图像开始(如海报艺术或产品摄影),并且你需要快速、惊人的动画,HappyHorse 1.0 是超凡的。强烈推荐用于短片叙事预告、风格化角色序列和快节奏社交媒体编辑。如果绝对的视觉连续性和电影氛围是你的首要任务,这个模型提供了令人惊叹的第一遍结果。
当使用 Seedance 2.0 时: Seedance 2.0 在复杂的导演风格工作流程中最闪亮。当你制作短剧、音乐视频或广告时,需要多个相机角度、同步口型运动和特定角色参考,Seedance 是明显的赢家。它处理多个参考的能力大大减少了繁琐的后期调整需求。此外,截至 2026 年初,Seedance 2.0 通过多种消费平台和可靠的 API 代理高度可访问,使其非常适合立即商业使用的制作就绪状态。
最终思考
AI 视频领域以惊人的速度发展,HappyHorse 1.0 和 Seedance 2.0 都在推动独立创作者能够实现的边界。HappyHorse 1.0 提供了无声视觉动作巅峰的鼓舞人心的一瞥,而 Seedance 2.0 提供了专业导演现在需要的强大、深度可控的工具。
我们强烈鼓励您试验这两个模型,看看哪一个自然地适合您的艺术过程。随着技术的不断成熟,我们无疑会看到更令人兴奋的更新。要随时了解最新的生成式 AI 趋势、教程和模型比较,请务必在 happyhorsesai.com 和我们一起探索更多资源!
撰文:HappyHorsesAI 研究团队
最后更新:2026 年 4 月 27 日